 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCzech Dataset for Cross-lingual Subjectivity Classification
Apr 29, 2022
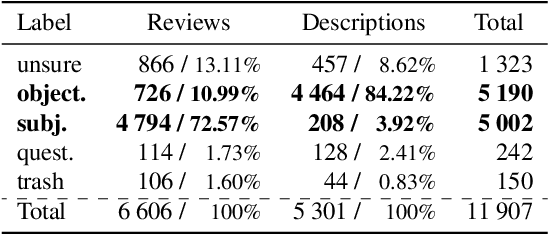
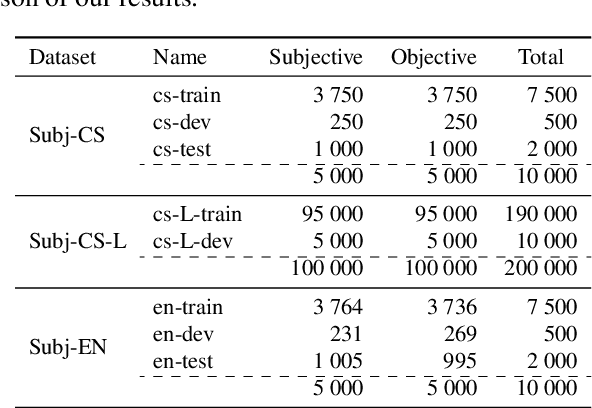

In this paper, we introduce a new Czech subjectivity dataset of 10k manually annotated subjective and objective sentences from movie reviews and descriptions. Our prime motivation is to provide a reliable dataset that can be used with the existing English dataset as a benchmark to test the ability of pre-trained multilingual models to transfer knowledge between Czech and English and vice versa. Two annotators annotated the dataset reaching 0.83 of the Cohen's \k{appa} inter-annotator agreement. To the best of our knowledge, this is the first subjectivity dataset for the Czech language. We also created an additional dataset that consists of 200k automatically labeled sentences. Both datasets are freely available for research purposes. Furthermore, we fine-tune five pre-trained BERT-like models to set a monolingual baseline for the new dataset and we achieve 93.56% of accuracy. We fine-tune models on the existing English dataset for which we obtained results that are on par with the current state-of-the-art results. Finally, we perform zero-shot cross-lingual subjectivity classification between Czech and English to verify the usability of our dataset as the cross-lingual benchmark. We compare and discuss the cross-lingual and monolingual results and the ability of multilingual models to transfer knowledge between languages.
Are the Multilingual Models Better? Improving Czech Sentiment with Transformers
Aug 24, 2021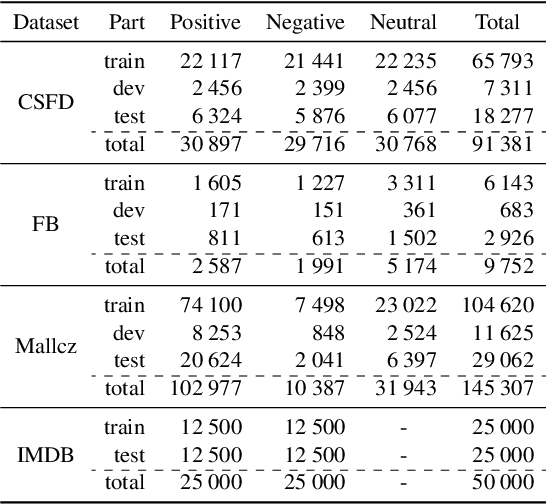
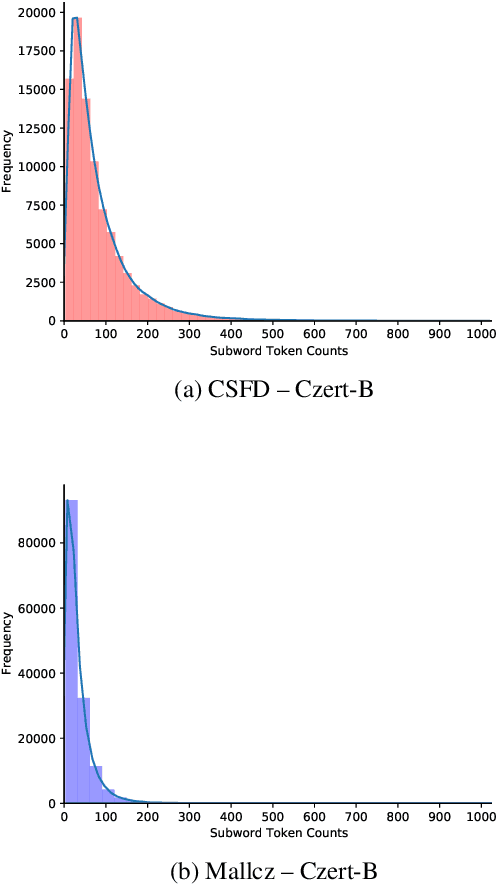
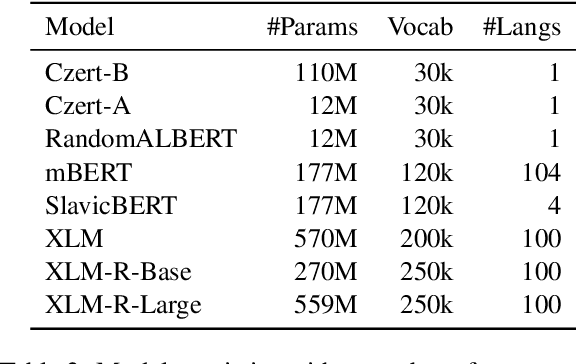
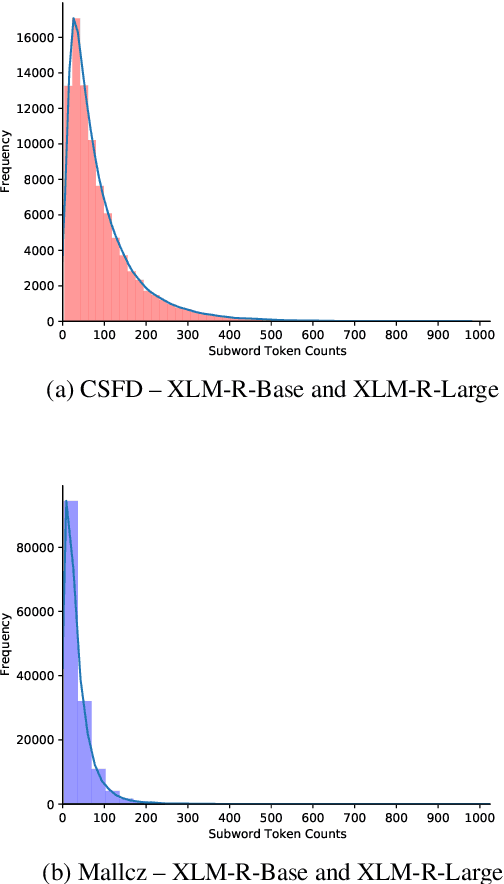
In this paper, we aim at improving Czech sentiment with transformer-based models and their multilingual versions. More concretely, we study the task of polarity detection for the Czech language on three sentiment polarity datasets. We fine-tune and perform experiments with five multilingual and three monolingual models. We compare the monolingual and multilingual models' performance, including comparison with the older approach based on recurrent neural networks. Furthermore, we test the multilingual models and their ability to transfer knowledge from English to Czech (and vice versa) with zero-shot cross-lingual classification. Our experiments show that the huge multilingual models can overcome the performance of the monolingual models. They are also able to detect polarity in another language without any training data, with performance not worse than 4.4 % compared to state-of-the-art monolingual trained models. Moreover, we achieved new state-of-the-art results on all three datasets.
Stance detection in online discussions
Jan 02, 2017
This paper describes our system created to detect stance in online discussions. The goal is to identify whether the author of a comment is in favor of the given target or against. Our approach is based on a maximum entropy classifier, which uses surface-level, sentiment and domain-specific features. The system was originally developed to detect stance in English tweets. We adapted it to process Czech news commentaries.