 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre the Multilingual Models Better? Improving Czech Sentiment with Transformers
Paper and Code
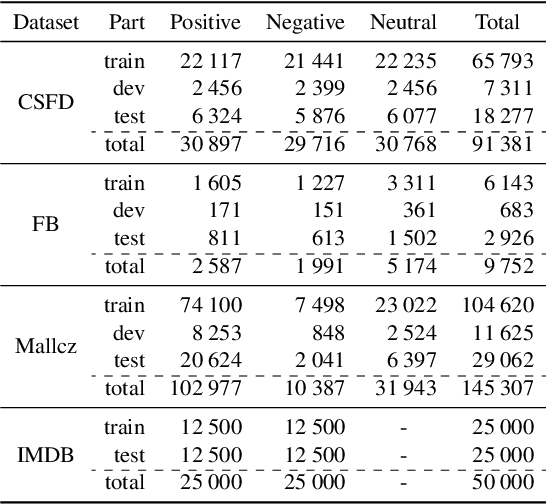
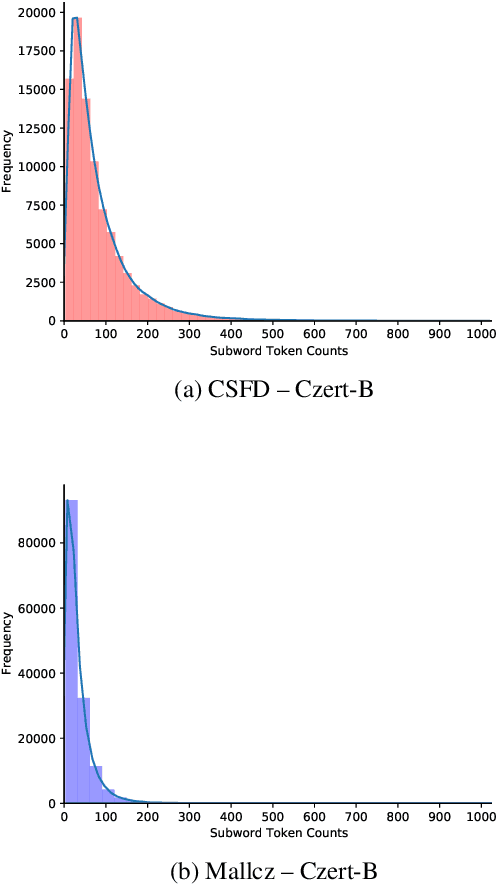
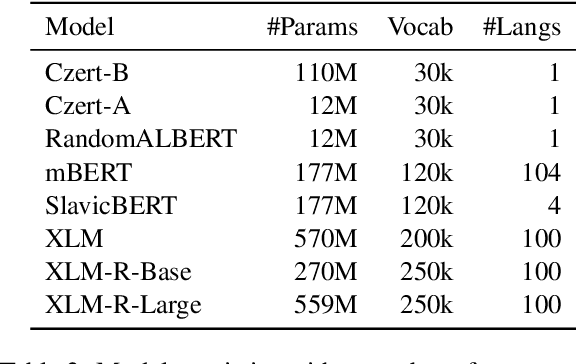
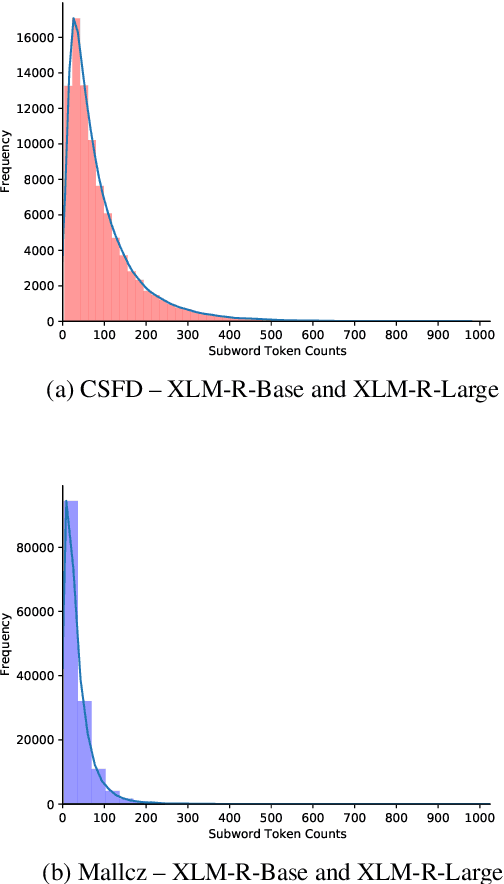
In this paper, we aim at improving Czech sentiment with transformer-based models and their multilingual versions. More concretely, we study the task of polarity detection for the Czech language on three sentiment polarity datasets. We fine-tune and perform experiments with five multilingual and three monolingual models. We compare the monolingual and multilingual models' performance, including comparison with the older approach based on recurrent neural networks. Furthermore, we test the multilingual models and their ability to transfer knowledge from English to Czech (and vice versa) with zero-shot cross-lingual classification. Our experiments show that the huge multilingual models can overcome the performance of the monolingual models. They are also able to detect polarity in another language without any training data, with performance not worse than 4.4 % compared to state-of-the-art monolingual trained models. Moreover, we achieved new state-of-the-art results on all three datasets.