 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Millimeter-Wave Radar System for Real-Time Multiple Human Tracking and Fall Detection
Mar 08, 2024



This study explores an indoor system for tracking multiple humans and detecting falls, employing three Millimeter-Wave radars from Texas Instruments placed on x-y-z surfaces. Compared to wearables and camera methods, Millimeter-Wave radar is not plagued by mobility inconvenience, lighting conditions, or privacy issues. We establish a real-time framework to integrate signals received from these radars, allowing us to track the position and body status of human targets non-intrusively. To ensure the overall accuracy of our system, we conduct an initial evaluation of radar characteristics, covering aspects such as resolution, interference between radars, and coverage area. Additionally, we introduce innovative strategies, including Dynamic DBSCAN clustering based on signal energy levels, a probability matrix for enhanced target tracking, target status prediction for fall detection, and a feedback loop for noise reduction. We conduct an extensive evaluation using over 300 minutes of data, which equates to approximately 360,000 frames. Our prototype system exhibits remarkable performance, achieving a precision of 98.9% for tracking a single target and 96.5% and 94.0% for tracking two and three targets in human tracking scenarios, respectively. Moreover, in the field of human fall detection, the system demonstrates a high accuracy of 98.2%, underscoring its effectiveness in distinguishing falls from other statuses.
Big-Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors
Apr 19, 2023

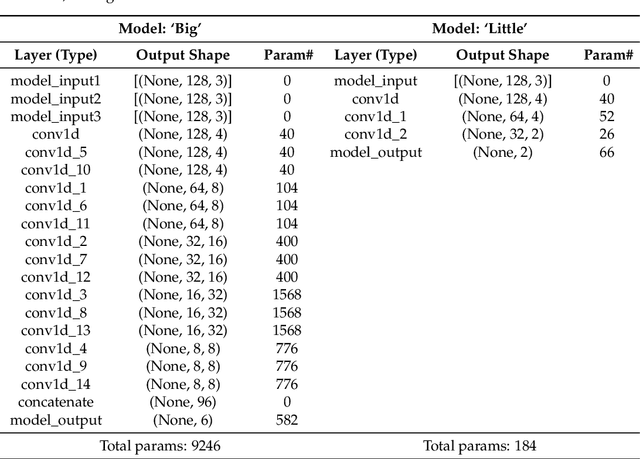

This paper investigates the energy savings that near-subthreshold processors can obtain in edge AI applications and proposes strategies to improve them while maintaining the accuracy of the application. The selected processors deploy adaptive voltage scaling techniques in which the frequency and voltage levels of the processor core are determined at the run-time. In these systems, embedded RAM and flash memory size is typically limited to less than 1 megabyte to save power. This limited memory imposes restrictions on the complexity of the neural networks model that can be mapped to these devices and the required trade-offs between accuracy and battery life. To address these issues, we propose and evaluate alternative 'big-little' neural network strategies to improve battery life while maintaining prediction accuracy. The strategies are applied to a human activity recognition application selected as a demonstrator that shows that compared to the original network, the best configurations obtain an energy reduction measured at 80% while maintaining the original level of inference accuracy.
* 27 pages, 17 figures, https://github.com/DarkSZChao/Big-Little_NN_Strategies
Dynamically Reconfigurable Variable-precision Sparse-Dense Matrix Acceleration in Tensorflow Lite
Apr 17, 2023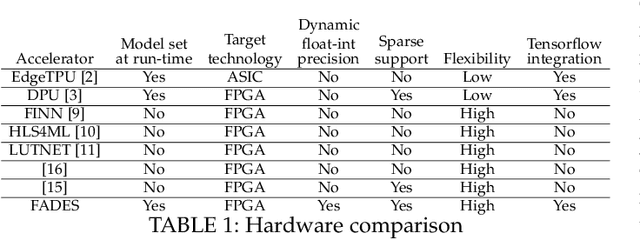
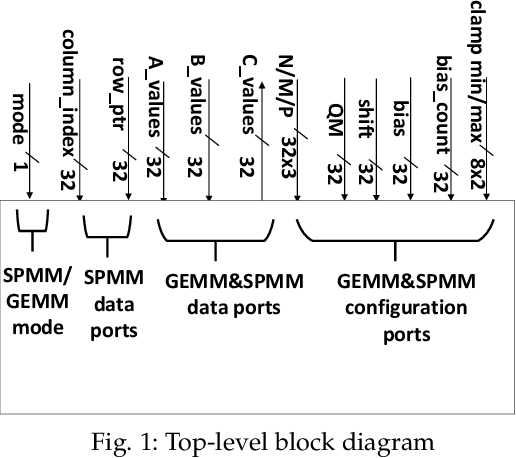
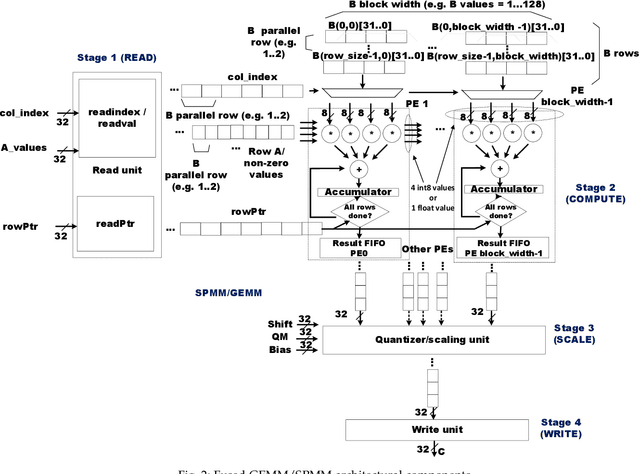
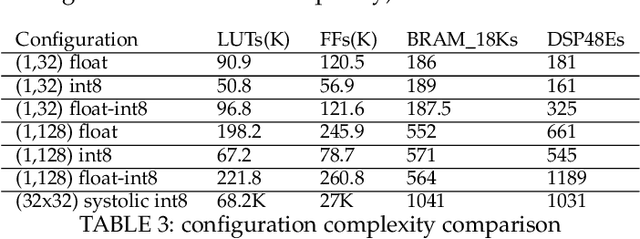
In this paper, we present a dynamically reconfigurable hardware accelerator called FADES (Fused Architecture for DEnse and Sparse matrices). The FADES design offers multiple configuration options that trade off parallelism and complexity using a dataflow model to create four stages that read, compute, scale and write results. FADES is mapped to the programmable logic (PL) and integrated with the TensorFlow Lite inference engine running on the processing system (PS) of a heterogeneous SoC device. The accelerator is used to compute the tensor operations, while the dynamically reconfigurable approach can be used to switch precision between int8 and float modes. This dynamic reconfiguration enables better performance by allowing more cores to be mapped to the resource-constrained device and lower power consumption compared with supporting both arithmetic precisions simultaneously. We compare the proposed hardware with a high-performance systolic architecture for dense matrices obtaining 25% better performance in dense mode with half the DSP blocks in the same technology. In sparse mode, we show that the core can outperform dense mode even at low sparsity levels, and a single-core achieves up to 20x acceleration over the software-optimized NEON RUY library.