 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Reconfigurable Variable-precision Sparse-Dense Matrix Acceleration in Tensorflow Lite
Paper and Code
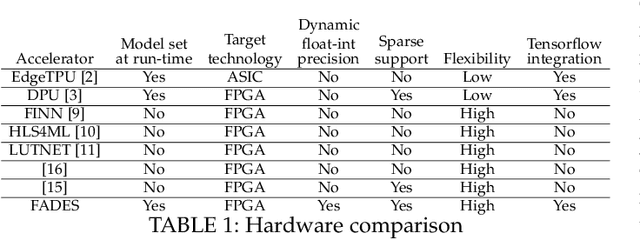
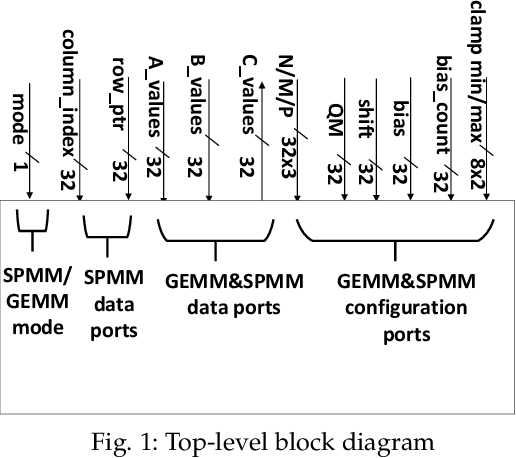
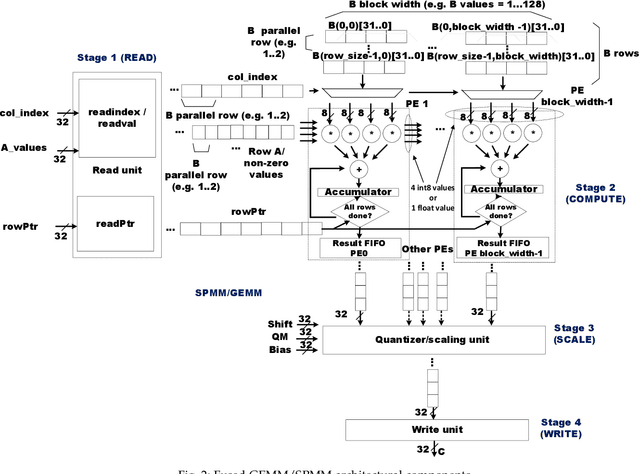
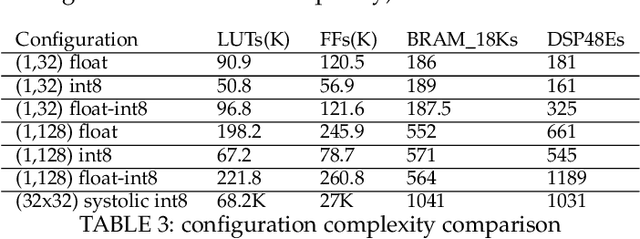
In this paper, we present a dynamically reconfigurable hardware accelerator called FADES (Fused Architecture for DEnse and Sparse matrices). The FADES design offers multiple configuration options that trade off parallelism and complexity using a dataflow model to create four stages that read, compute, scale and write results. FADES is mapped to the programmable logic (PL) and integrated with the TensorFlow Lite inference engine running on the processing system (PS) of a heterogeneous SoC device. The accelerator is used to compute the tensor operations, while the dynamically reconfigurable approach can be used to switch precision between int8 and float modes. This dynamic reconfiguration enables better performance by allowing more cores to be mapped to the resource-constrained device and lower power consumption compared with supporting both arithmetic precisions simultaneously. We compare the proposed hardware with a high-performance systolic architecture for dense matrices obtaining 25% better performance in dense mode with half the DSP blocks in the same technology. In sparse mode, we show that the core can outperform dense mode even at low sparsity levels, and a single-core achieves up to 20x acceleration over the software-optimized NEON RUY library.