 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Orthogonal Latent Components Analysis (POLCA Net)
Oct 09, 2024Representation learning is a pivotal area in the field of machine learning, focusing on the development of methods to automatically discover the representations or features needed for a given task from raw data. Unlike traditional feature engineering, which requires manual crafting of features, representation learning aims to learn features that are more useful and relevant for tasks such as classification, prediction, and clustering. We introduce Principal Orthogonal Latent Components Analysis Network (POLCA Net), an approach to mimic and extend PCA and LDA capabilities to non-linear domains. POLCA Net combines an autoencoder framework with a set of specialized loss functions to achieve effective dimensionality reduction, orthogonality, variance-based feature sorting, high-fidelity reconstructions, and additionally, when used with classification labels, a latent representation well suited for linear classifiers and low dimensional visualization of class distribution as well.
Reinforcement Learning in System Identification
Dec 14, 2022



System identification, also known as learning forward models, transfer functions, system dynamics, etc., has a long tradition both in science and engineering in different fields. Particularly, it is a recurring theme in Reinforcement Learning research, where forward models approximate the state transition function of a Markov Decision Process by learning a mapping function from current state and action to the next state. This problem is commonly defined as a Supervised Learning problem in a direct way. This common approach faces several difficulties due to the inherent complexities of the dynamics to learn, for example, delayed effects, high non-linearity, non-stationarity, partial observability and, more important, error accumulation when using bootstrapped predictions (predictions based on past predictions), over large time horizons. Here we explore the use of Reinforcement Learning in this problem. We elaborate on why and how this problem fits naturally and sound as a Reinforcement Learning problem, and present some experimental results that demonstrate RL is a promising technique to solve these kind of problems.
Dyna-H: a heuristic planning reinforcement learning algorithm applied to role-playing-game strategy decision systems
Jul 30, 2011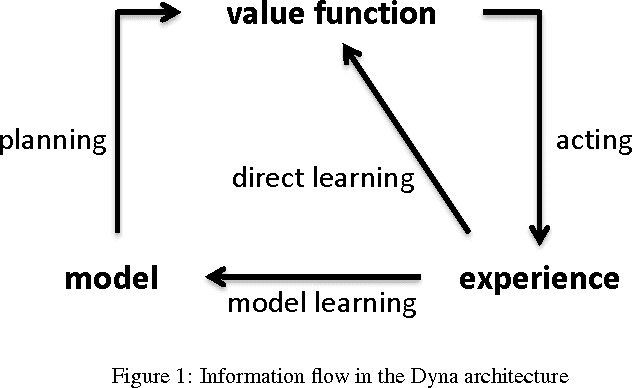
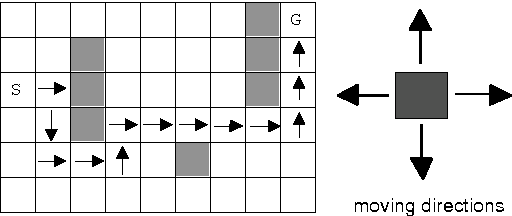

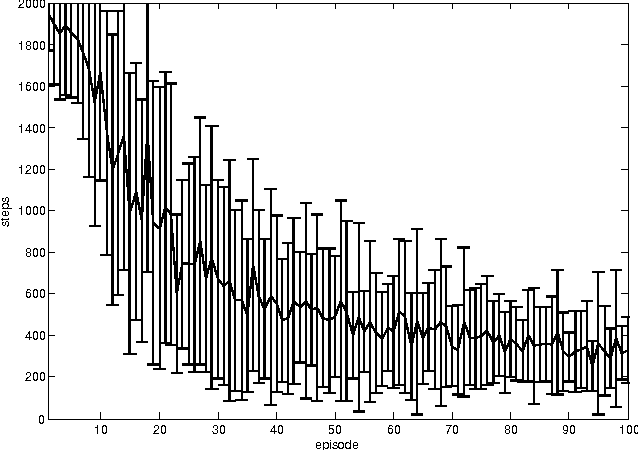
In a Role-Playing Game, finding optimal trajectories is one of the most important tasks. In fact, the strategy decision system becomes a key component of a game engine. Determining the way in which decisions are taken (online, batch or simulated) and the consumed resources in decision making (e.g. execution time, memory) will influence, in mayor degree, the game performance. When classical search algorithms such as A* can be used, they are the very first option. Nevertheless, such methods rely on precise and complete models of the search space, and there are many interesting scenarios where their application is not possible. Then, model free methods for sequential decision making under uncertainty are the best choice. In this paper, we propose a heuristic planning strategy to incorporate the ability of heuristic-search in path-finding into a Dyna agent. The proposed Dyna-H algorithm, as A* does, selects branches more likely to produce outcomes than other branches. Besides, it has the advantages of being a model-free online reinforcement learning algorithm. The proposal was evaluated against the one-step Q-Learning and Dyna-Q algorithms obtaining excellent experimental results: Dyna-H significantly overcomes both methods in all experiments. We suggest also, a functional analogy between the proposed sampling from worst trajectories heuristic and the role of dreams (e.g. nightmares) in human behavior.