 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYotoR-You Only Transform One Representation
May 30, 2024


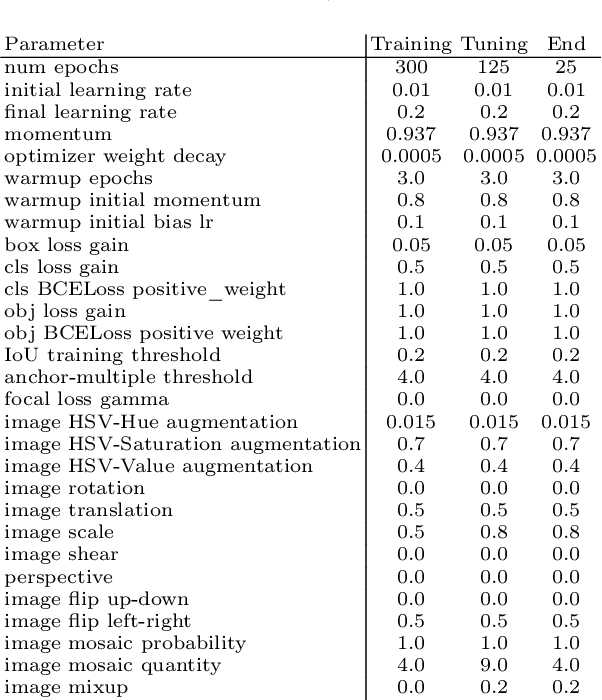
This paper introduces YotoR (You Only Transform One Representation), a novel deep learning model for object detection that combines Swin Transformers and YoloR architectures. Transformers, a revolutionary technology in natural language processing, have also significantly impacted computer vision, offering the potential to enhance accuracy and computational efficiency. YotoR combines the robust Swin Transformer backbone with the YoloR neck and head. In our experiments, YotoR models TP5 and BP4 consistently outperform YoloR P6 and Swin Transformers in various evaluations, delivering improved object detection performance and faster inference speeds than Swin Transformer models. These results highlight the potential for further model combinations and improvements in real-time object detection with Transformers. The paper concludes by emphasizing the broader implications of YotoR, including its potential to enhance transformer-based models for image-related tasks.