 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypergraph-of-Entity: A General Model for Entity-Oriented Search
Sep 01, 2021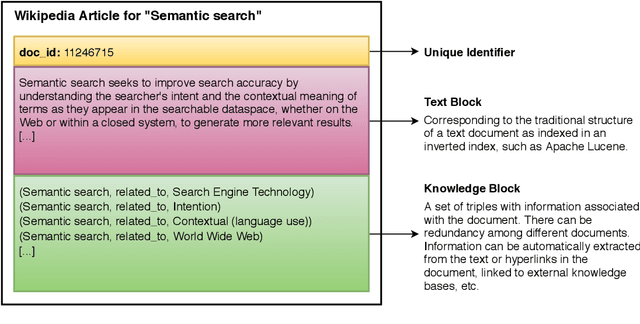

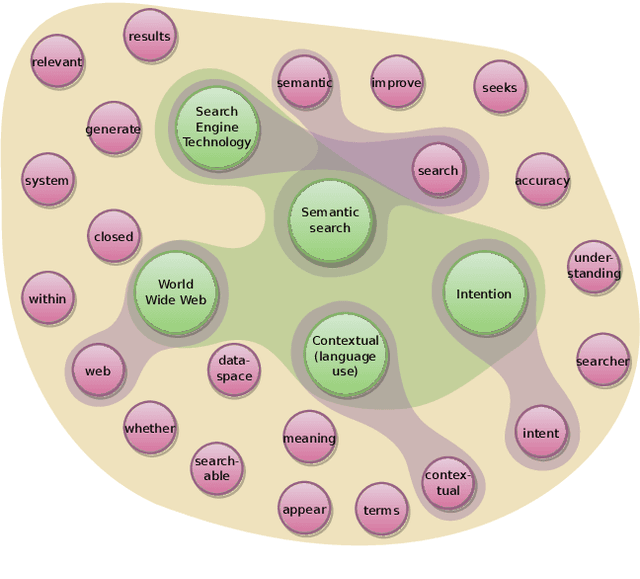
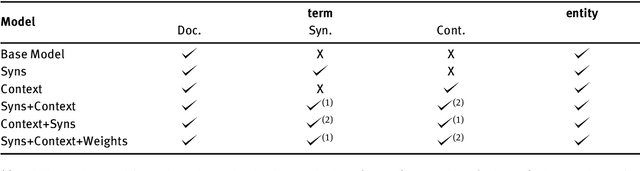
The hypergraph-of-entity was conceptually proposed as a general model for entity-oriented search. However, only the performance for ad hoc document retrieval had been assessed. We continue this line of research by also evaluating ad hoc entity retrieval, and entity list completion. We also attempt to scale the model, so that it can support the complete INEX 2009 Wikipedia collection. We do this by indexing the top keywords for each document, reducing complexity by partially lowering the number of nodes and, indirectly, the number of hyperedges linking terms to entities. This enables us to compare the effectiveness of the hypergraph-of-entity with the results obtained by the participants of the INEX tracks for the considered tasks. We find this to be a viable model that is, to our knowledge, the first attempt at a generalization in information retrieval, in particular by supporting a universal ranking function for multiple entity-oriented search tasks.
Fatigued PageRank
Apr 14, 2021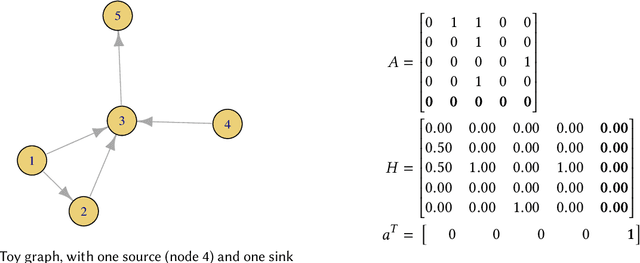

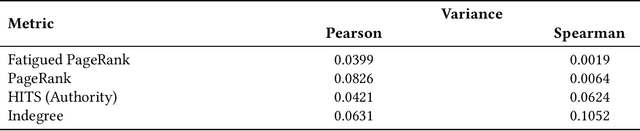
Connections among entities are everywhere. From social media interactions to web page hyperlinks, networks are frequently used to represent such complex systems. Node ranking is a fundamental task that provides the strategy to identify central entities according to multiple criteria. Popular node ranking metrics include degree, closeness or betweenness centralities, as well as HITS authority or PageRank. In this work, we propose a novel node ranking metric, where we combine PageRank and the idea of node fatigue, in order to model a random explorer who wants to optimize coverage - it gets fatigued and avoids previously visited nodes. We formalize and exemplify the computation of Fatigued PageRank, evaluating it as a node ranking metric, as well as query-independent evidence in ad hoc document retrieval. Based on the Simple English Wikipedia link graph with clickstream transitions from the English Wikipedia, we find that Fatigued PageRank is able to surpass both indegree and HITS authority, but only for the top ranking nodes. On the other hand, based on the TREC Washington Post Corpus, we were unable to outperform the BM25 baseline, obtaining similar performance for all graph-based metrics, except for indegree, which lowered GMAP and MAP, but increased NDCG@10 and P@10.
Fatigued Random Walks in Hypergraphs: A Neuronal Analogy to Improve Retrieval Performance
Apr 12, 2021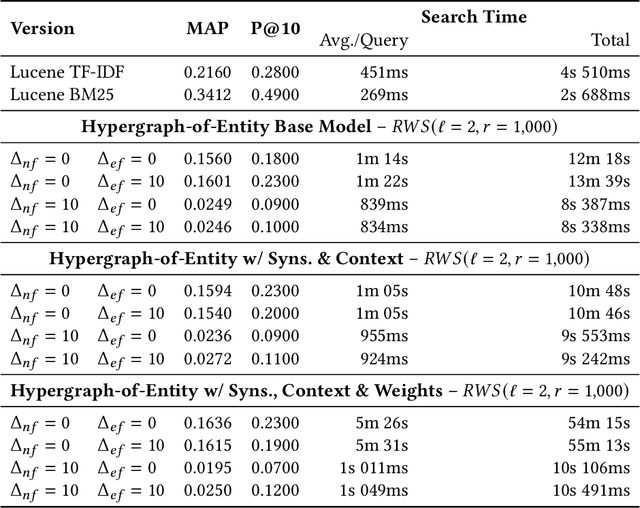
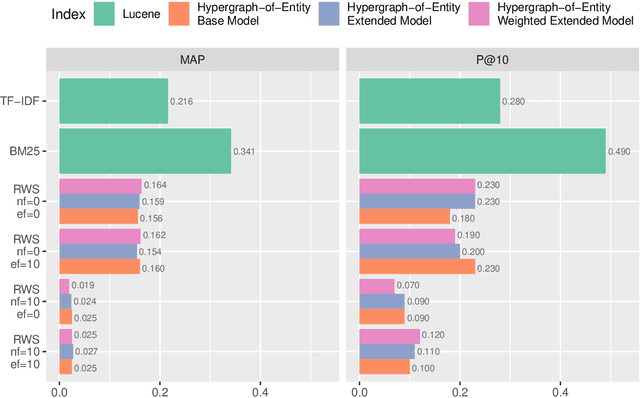
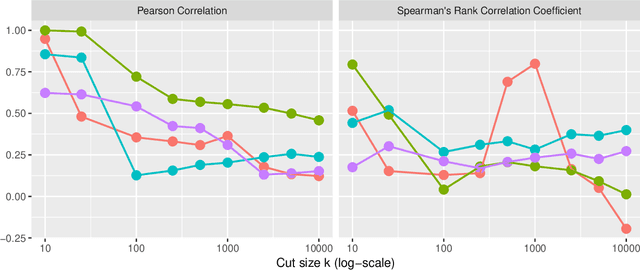
Hypergraphs are data structures capable of capturing supra-dyadic relations. We can use them to model binary relations, but also to model groups of entities, as well as the intersections between these groups or the contained subgroups. In previous work, we explored the usage of hypergraphs as an indexing data structure, in particular one that was capable of seamlessly integrating text, entities and their relations to support entity-oriented search tasks. As more information is added to the hypergraph, however, it not only increases in size, but it also becomes denser, making the task of efficiently ranking nodes or hyperedges more complex. Random walks can effectively capture network structure, without compromising performance, or at least providing a tunable balance between efficiency and effectiveness, within a nondeterministic universe. For a higher effectiveness, a higher number of random walks is usually required, which often results in lower efficiency. Inspired by von Neumann and the neuron in the brain, we propose and study the usage of node and hyperedge fatigue as a way to temporarily constrict random walks during keyword-based ad hoc retrieval. We found that we were able to improve search time by a factor of 32, but also worsen MAP by a factor of 8. Moreover, by distinguishing between fatigue in nodes and hyperedges, we are able to find that, for hyperedge ranking tasks, we consistently obtained lower MAP scores when increasing fatigue for nodes. On the other hand, the overall impact of hyperedge fatigue was slightly positive, although it also slightly worsened efficiency.