 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDS++: Online Situation-Aware Drivable Space Estimation for Automated Driving
Jun 04, 2024



Autonomous Vehicles (AVs) need an accurate and up-to-date representation of the environment for safe navigation. Traditional methods, which often rely on detailed environmental representations constructed offline, struggle in dynamically changing environments or when dealing with outdated maps. Consequently, there is a pressing need for real-time solutions that can integrate diverse data sources and adapt to the current situation. An existing framework that addresses these challenges is SDS (situation-aware drivable space). However, SDS faces several limitations, including its use of a non-standard output representation, its choice of encoding objects as points, restricting representation of more complex geometries like road lanes, and the fact that its methodology has been validated only with simulated or heavily post-processed data. This work builds upon SDS and introduces SDS++, designed to overcome SDS's shortcomings while preserving its benefits. SDS++ has been rigorously validated not only in simulations but also with unrefined vehicle data, and it is integrated with a model predictive control (MPC)-based planner to verify its advantages for the planning task. The results demonstrate that SDS++ significantly enhances trajectory planning capabilities, providing increased robustness against localization noise, and enabling the planning of trajectories that adapt to the current driving context.
Prediction Horizon Requirements for Automated Driving: Optimizing Safety, Comfort, and Efficiency
Feb 06, 2024
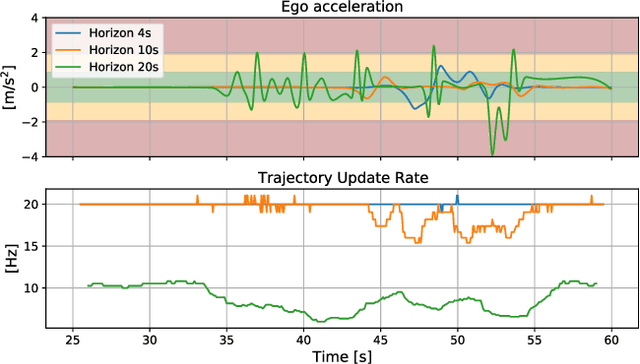
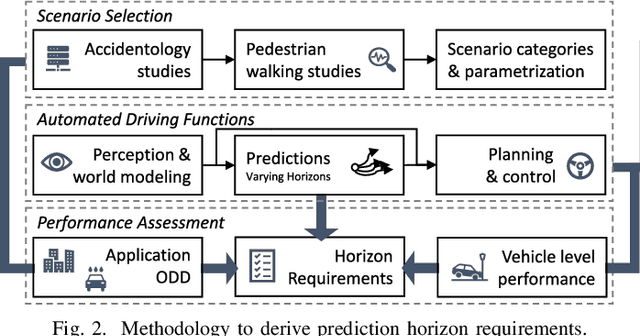

Predicting the movement of other road users is beneficial for improving automated vehicle (AV) performance. However, the relationship between the time horizon associated with these predictions and AV performance remains unclear. Despite the existence of numerous trajectory prediction algorithms, no studies have been conducted on how varying prediction lengths affect AV safety and other vehicle performance metrics, resulting in undefined horizon requirements for prediction methods. Our study addresses this gap by examining the effects of different prediction horizons on AV performance, focusing on safety, comfort, and efficiency. Through multiple experiments using a state-of-the-art, risk-based predictive trajectory planner, we simulated predictions with horizons up to 20 seconds. Based on our simulations, we propose a framework for specifying the minimum required and optimal prediction horizons based on specific AV performance criteria and application needs. Our results indicate that a horizon of 1.6 seconds is required to prevent collisions with crossing pedestrians, horizons of 7-8 seconds yield the best efficiency, and horizons up to 15 seconds improve passenger comfort. We conclude that prediction horizon requirements are application-dependent, and recommend aiming for a prediction horizon of 11.8 seconds as a general guideline for applications involving crossing pedestrians.
Robustness Benchmark of Road User Trajectory Prediction Models for Automated Driving
Apr 04, 2023Accurate and robust trajectory predictions of road users are needed to enable safe automated driving. To do this, machine learning models are often used, which can show erratic behavior when presented with previously unseen inputs. In this work, two environment-aware models (MotionCNN and MultiPath++) and two common baselines (Constant Velocity and an LSTM) are benchmarked for robustness against various perturbations that simulate functional insufficiencies observed during model deployment in a vehicle: unavailability of road information, late detections, and noise. Results show significant performance degradation under the presence of these perturbations, with errors increasing up to +1444.8\% in commonly used trajectory prediction evaluation metrics. Training the models with similar perturbations effectively reduces performance degradation, with error increases of up to +87.5\%. We argue that despite being an effective mitigation strategy, data augmentation through perturbations during training does not guarantee robustness towards unforeseen perturbations, since identification of all possible on-road complications is unfeasible. Furthermore, degrading the inputs sometimes leads to more accurate predictions, suggesting that the models are unable to learn the true relationships between the different elements in the data.