 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net-and-a-half: Convolutional network for biomedical image segmentation using multiple expert-driven annotations
Aug 10, 2021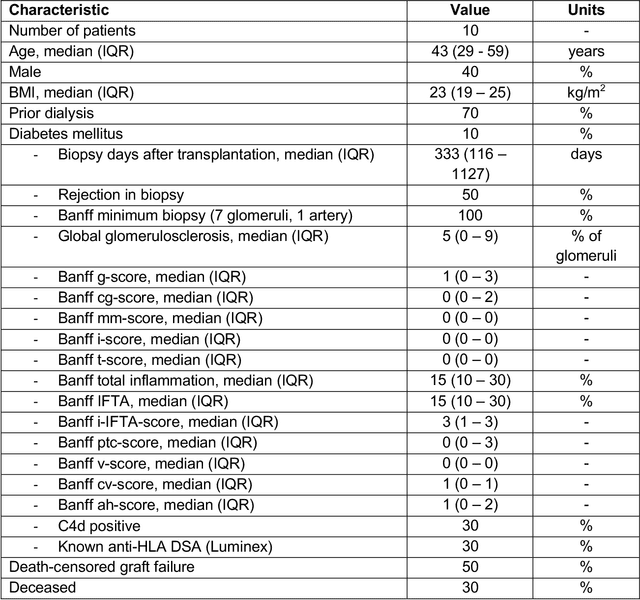
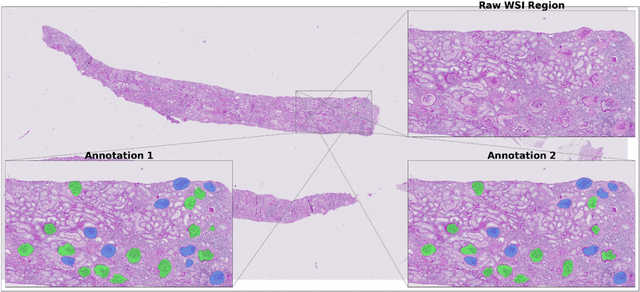

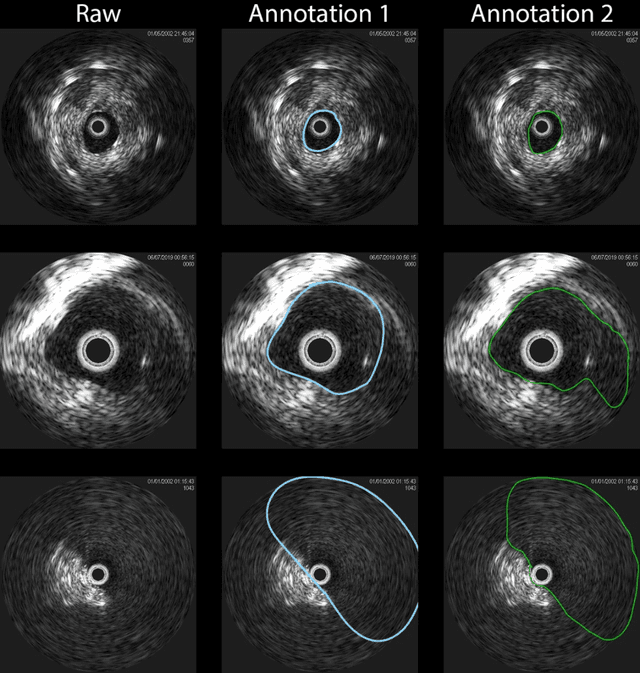
Development of deep learning systems for biomedical segmentation often requires access to expert-driven, manually annotated datasets. If more than a single expert is involved in the annotation of the same images, then the inter-expert agreement is not necessarily perfect, and no single expert annotation can precisely capture the so-called ground truth of the regions of interest on all images. Also, it is not trivial to generate a reference estimate using annotations from multiple experts. Here we present a deep neural network, defined as U-Net-and-a-half, which can simultaneously learn from annotations performed by multiple experts on the same set of images. U-Net-and-a-half contains a convolutional encoder to generate features from the input images, multiple decoders that allow simultaneous learning from image masks obtained from annotations that were independently generated by multiple experts, and a shared low-dimensional feature space. To demonstrate the applicability of our framework, we used two distinct datasets from digital pathology and radiology, respectively. Specifically, we trained two separate models using pathologist-driven annotations of glomeruli on whole slide images of human kidney biopsies (10 patients), and radiologist-driven annotations of lumen cross-sections of human arteriovenous fistulae obtained from intravascular ultrasound images (10 patients), respectively. The models based on U-Net-and-a-half exceeded the performance of the traditional U-Net models trained on single expert annotations alone, thus expanding the scope of multitask learning in the context of biomedical image segmentation.