 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling representations in Restricted Boltzmann Machines without adversaries
Jul 01, 2022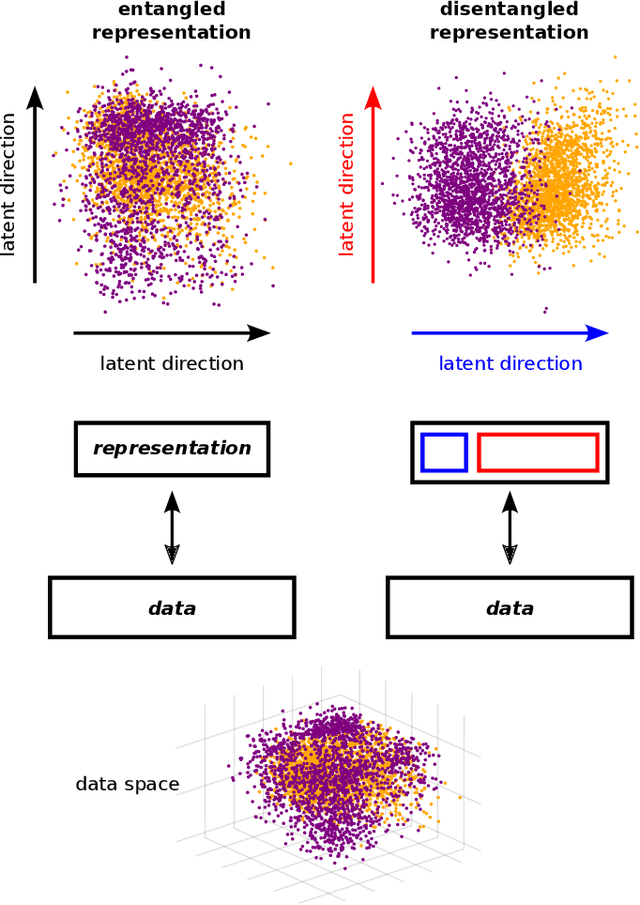
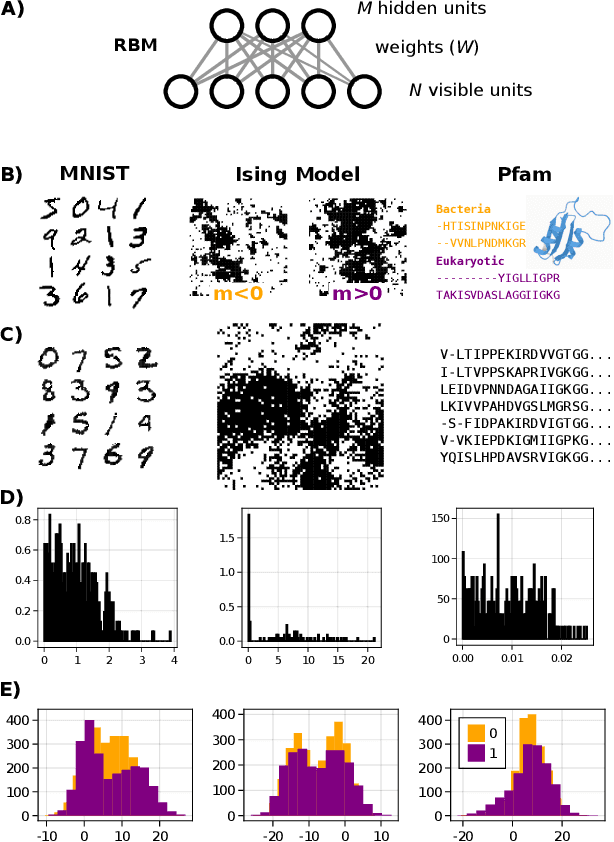
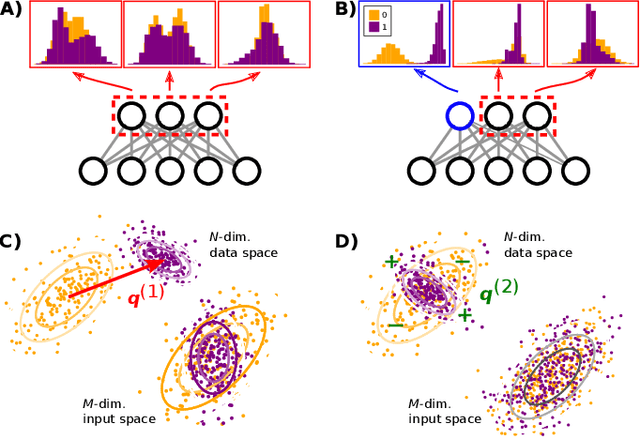
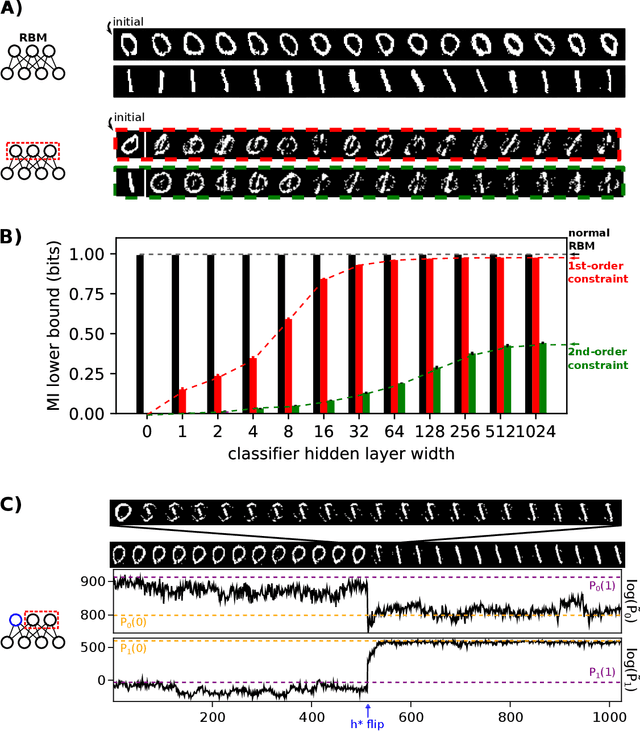
A goal of unsupervised machine learning is to disentangle representations of complex high-dimensional data, allowing for interpreting the significant latent factors of variation in the data as well as for manipulating them to generate new data with desirable features. These methods often rely on an adversarial scheme, in which representations are tuned to avoid discriminators from being able to reconstruct specific data information (labels). We propose a simple, effective way of disentangling representations without any need to train adversarial discriminators, and apply our approach to Restricted Boltzmann Machines (RBM), one of the simplest representation-based generative models. Our approach relies on the introduction of adequate constraints on the weights during training, which allows us to concentrate information about labels on a small subset of latent variables. The effectiveness of the approach is illustrated on the MNIST dataset, the two-dimensional Ising model, and taxonomy of protein families. In addition, we show how our framework allows for computing the cost, in terms of log-likelihood of the data, associated to the disentanglement of their representations.