 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparency and Proportionality in Post-Processing Algorithmic Bias Correction
May 23, 2025
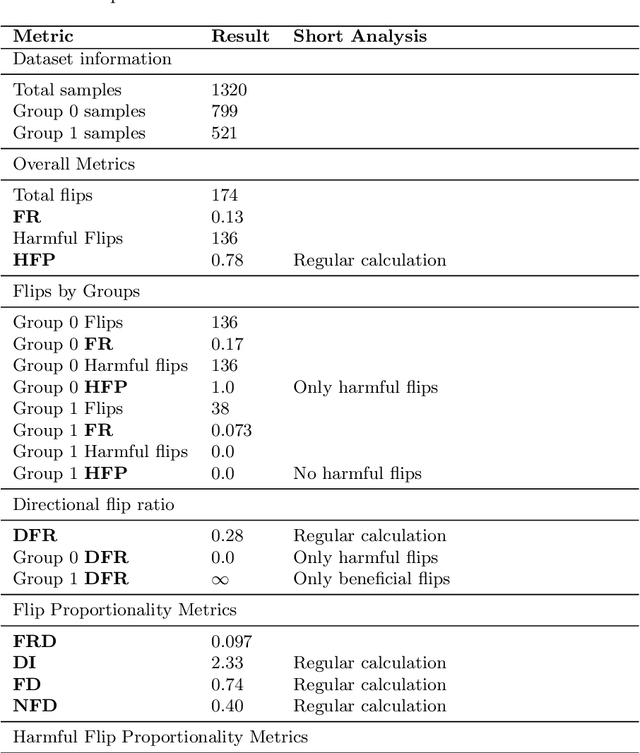


Algorithmic decision-making systems sometimes produce errors or skewed predictions toward a particular group, leading to unfair results. Debiasing practices, applied at different stages of the development of such systems, occasionally introduce new forms of unfairness or exacerbate existing inequalities. We focus on post-processing techniques that modify algorithmic predictions to achieve fairness in classification tasks, examining the unintended consequences of these interventions. To address this challenge, we develop a set of measures that quantify the disparity in the flips applied to the solution in the post-processing stage. The proposed measures will help practitioners: (1) assess the proportionality of the debiasing strategy used, (2) have transparency to explain the effects of the strategy in each group, and (3) based on those results, analyze the possibility of the use of some other approaches for bias mitigation or to solve the problem. We introduce a methodology for applying the proposed metrics during the post-processing stage and illustrate its practical application through an example. This example demonstrates how analyzing the proportionality of the debiasing strategy complements traditional fairness metrics, providing a deeper perspective to ensure fairer outcomes across all groups.
Uncovering Fairness through Data Complexity as an Early Indicator
Apr 08, 2025Fairness constitutes a concern within machine learning (ML) applications. Currently, there is no study on how disparities in classification complexity between privileged and unprivileged groups could influence the fairness of solutions, which serves as a preliminary indicator of potential unfairness. In this work, we investigate this gap, specifically, we focus on synthetic datasets designed to capture a variety of biases ranging from historical bias to measurement and representational bias to evaluate how various complexity metrics differences correlate with group fairness metrics. We then apply association rule mining to identify patterns that link disproportionate complexity differences between groups with fairness-related outcomes, offering data-centric indicators to guide bias mitigation. Our findings are also validated by their application in real-world problems, providing evidence that quantifying group-wise classification complexity can uncover early indicators of potential fairness challenges. This investigation helps practitioners to proactively address bias in classification tasks.
Am I Being Treated Fairly? A Conceptual Framework for Individuals to Ascertain Fairness
Apr 03, 2025Current fairness metrics and mitigation techniques provide tools for practitioners to asses how non-discriminatory Automatic Decision Making (ADM) systems are. What if I, as an individual facing a decision taken by an ADM system, would like to know: Am I being treated fairly? We explore how to create the affordance for users to be able to ask this question of ADM. In this paper, we argue for the reification of fairness not only as a property of ADM, but also as an epistemic right of an individual to acquire information about the decisions that affect them and use that information to contest and seek effective redress against those decisions, in case they are proven to be discriminatory. We examine key concepts from existing research not only in algorithmic fairness but also in explainable artificial intelligence, accountability, and contestability. Integrating notions from these domains, we propose a conceptual framework to ascertain fairness by combining different tools that empower the end-users of ADM systems. Our framework shifts the focus from technical solutions aimed at practitioners to mechanisms that enable individuals to understand, challenge, and verify the fairness of decisions, and also serves as a blueprint for organizations and policymakers, bridging the gap between technical requirements and practical, user-centered accountability.
How fair can we go in machine learning? Assessing the boundaries of fairness in decision trees
Jun 22, 2020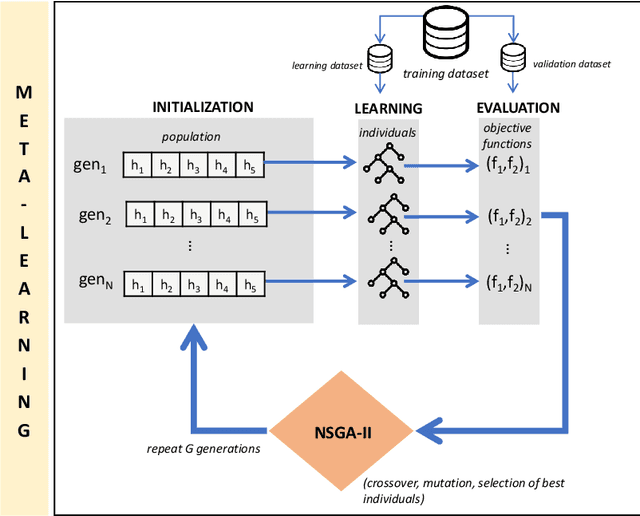


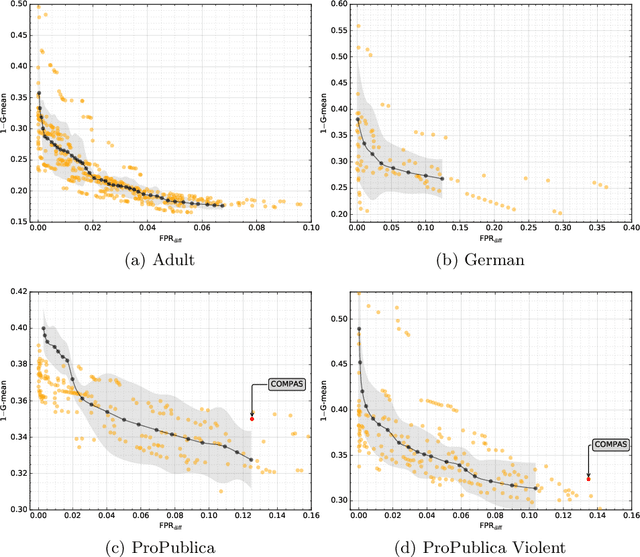
Fair machine learning works have been focusing on the development of equitable algorithms that address discrimination of certain groups. Yet, many of these fairness-aware approaches aim to obtain a unique solution to the problem, which leads to a poor understanding of the statistical limits of bias mitigation interventions. We present the first methodology that allows to explore those limits within a multi-objective framework that seeks to optimize any measure of accuracy and fairness and provides a Pareto front with the best feasible solutions. In this work, we focus our study on decision tree classifiers since they are widely accepted in machine learning, are easy to interpret and can deal with non-numerical information naturally. We conclude experimentally that our method can optimize decision tree models by being fairer with a small cost of the classification error. We believe that our contribution will help stakeholders of sociotechnical systems to assess how far they can go being fair and accurate, thus serving in the support of enhanced decision making where machine learning is used.