 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Convolutional Neural Networks under Adversarial Noise
Feb 25, 2016
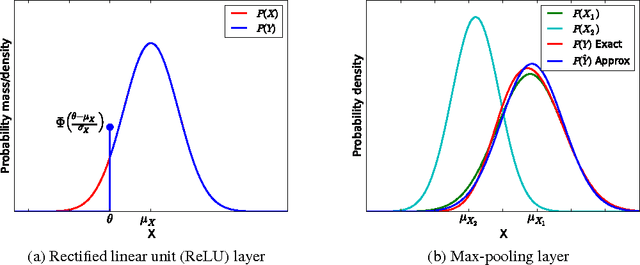
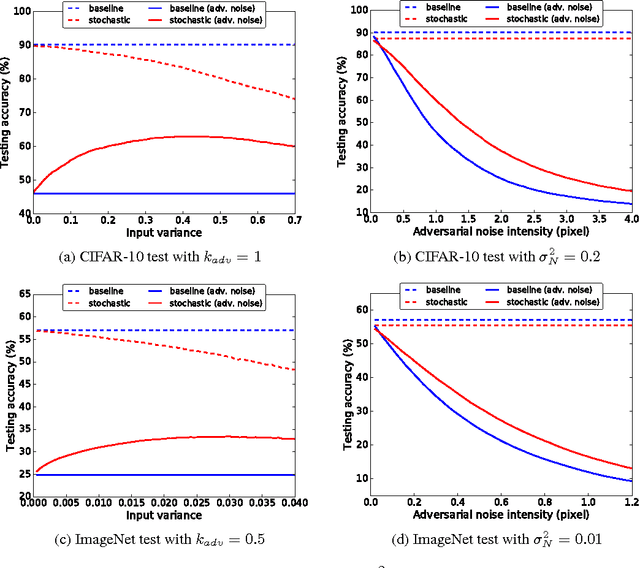
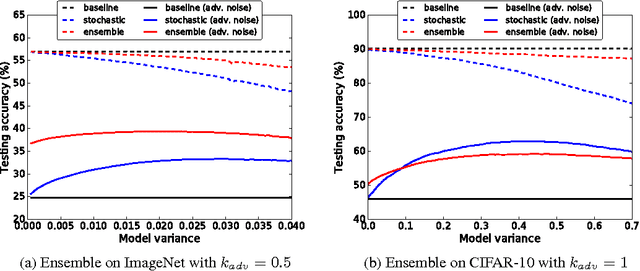
Recent studies have shown that Convolutional Neural Networks (CNNs) are vulnerable to a small perturbation of input called "adversarial examples". In this work, we propose a new feedforward CNN that improves robustness in the presence of adversarial noise. Our model uses stochastic additive noise added to the input image and to the CNN models. The proposed model operates in conjunction with a CNN trained with either standard or adversarial objective function. In particular, convolution, max-pooling, and ReLU layers are modified to benefit from the noise model. Our feedforward model is parameterized by only a mean and variance per pixel which simplifies computations and makes our method scalable to a deep architecture. From CIFAR-10 and ImageNet test, the proposed model outperforms other methods and the improvement is more evident for difficult classification tasks or stronger adversarial noise.
Convolutional Clustering for Unsupervised Learning
Feb 16, 2016


The task of labeling data for training deep neural networks is daunting and tedious, requiring millions of labels to achieve the current state-of-the-art results. Such reliance on large amounts of labeled data can be relaxed by exploiting hierarchical features via unsupervised learning techniques. In this work, we propose to train a deep convolutional network based on an enhanced version of the k-means clustering algorithm, which reduces the number of correlated parameters in the form of similar filters, and thus increases test categorization accuracy. We call our algorithm convolutional k-means clustering. We further show that learning the connection between the layers of a deep convolutional neural network improves its ability to be trained on a smaller amount of labeled data. Our experiments show that the proposed algorithm outperforms other techniques that learn filters unsupervised. Specifically, we obtained a test accuracy of 74.1% on STL-10 and a test error of 0.5% on MNIST.
Flattened Convolutional Neural Networks for Feedforward Acceleration
Nov 20, 2015


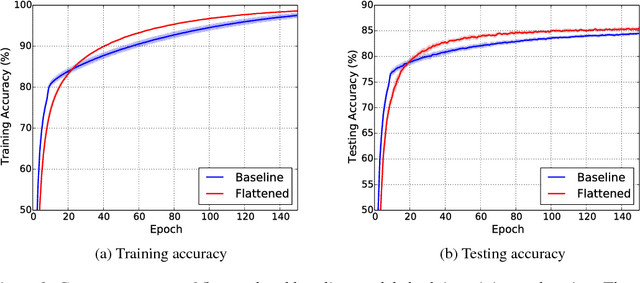
We present flattened convolutional neural networks that are designed for fast feedforward execution. The redundancy of the parameters, especially weights of the convolutional filters in convolutional neural networks has been extensively studied and different heuristics have been proposed to construct a low rank basis of the filters after training. In this work, we train flattened networks that consist of consecutive sequence of one-dimensional filters across all directions in 3D space to obtain comparable performance as conventional convolutional networks. We tested flattened model on different datasets and found that the flattened layer can effectively substitute for the 3D filters without loss of accuracy. The flattened convolution pipelines provide around two times speed-up during feedforward pass compared to the baseline model due to the significant reduction of learning parameters. Furthermore, the proposed method does not require efforts in manual tuning or post processing once the model is trained.
An Analysis of the Connections Between Layers of Deep Neural Networks
Jun 01, 2013
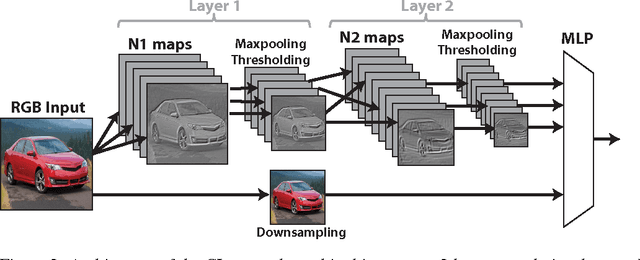


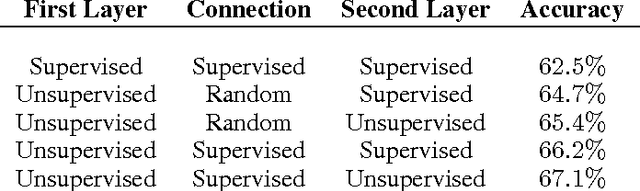
We present an analysis of different techniques for selecting the connection be- tween layers of deep neural networks. Traditional deep neural networks use ran- dom connection tables between layers to keep the number of connections small and tune to different image features. This kind of connection performs adequately in supervised deep networks because their values are refined during the training. On the other hand, in unsupervised learning, one cannot rely on back-propagation techniques to learn the connections between layers. In this work, we tested four different techniques for connecting the first layer of the network to the second layer on the CIFAR and SVHN datasets and showed that the accuracy can be im- proved up to 3% depending on the technique used. We also showed that learning the connections based on the co-occurrences of the features does not confer an advantage over a random connection table in small networks. This work is helpful to improve the efficiency of connections between the layers of unsupervised deep neural networks.
Visual Tracking with Similarity Matching Ratio
Sep 12, 2012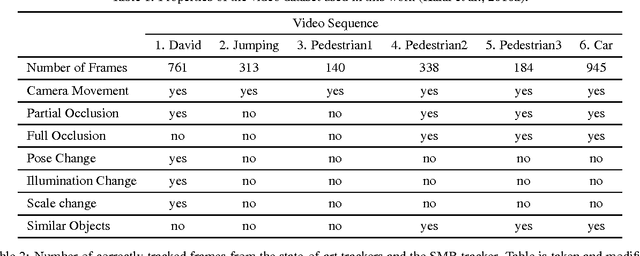



This paper presents a novel approach to visual tracking: Similarity Matching Ratio (SMR). The traditional approach of tracking is minimizing some measures of the difference between the template and a patch from the frame. This approach is vulnerable to outliers and drastic appearance changes and an extensive study is focusing on making the approach more tolerant to them. However, this often results in longer, corrective algo- rithms which do not solve the original problem. This paper proposes a novel approach to the definition of the tracking problems, SMR, which turns the differences into a probability measure. Only pixel differences below a threshold count towards deciding the match, the rest are ignored. This approach makes the SMR tracker robust to outliers and points that dramaticaly change appearance. The SMR tracker is tested on challenging video sequences and achieved state-of-the-art performance.