 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Estimation Using Round-trip Translation with Sentence Embeddings
Oct 31, 2021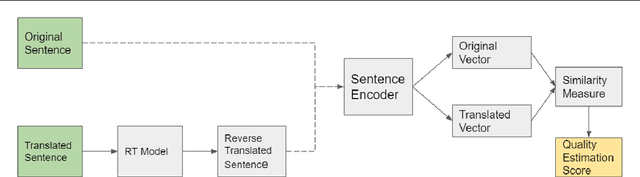
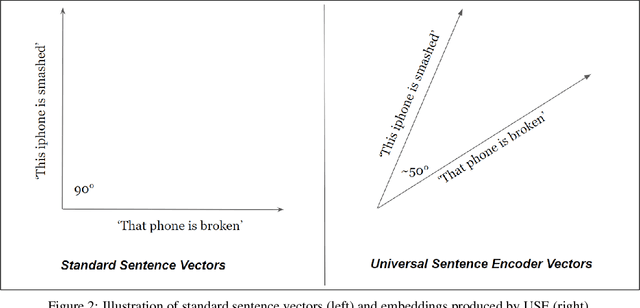

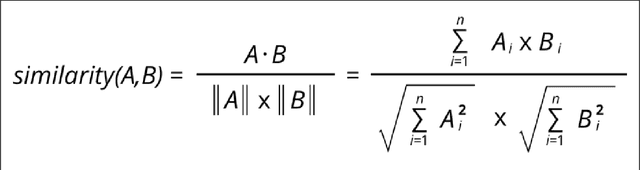
Estimating the quality of machine translation systems has been an ongoing challenge for researchers in this field. Many previous attempts at using round-trip translation as a measure of quality have failed, and there is much disagreement as to whether it can be a viable method of quality estimation. In this paper, we revisit round-trip translation, proposing a system which aims to solve the previous pitfalls found with the approach. Our method makes use of recent advances in language representation learning to more accurately gauge the similarity between the original and round-trip translated sentences. Experiments show that while our approach does not reach the performance of current state of the art methods, it may still be an effective approach for some language pairs.
Generation of Synthetic Electronic Health Records Using a Federated GAN
Sep 06, 2021
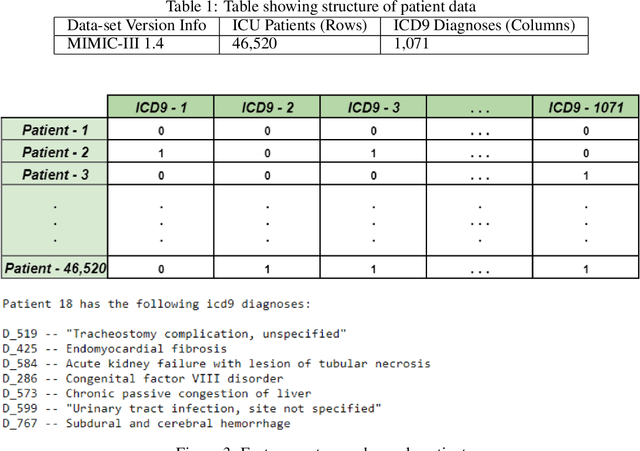
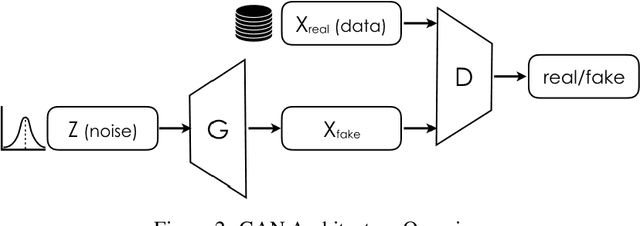
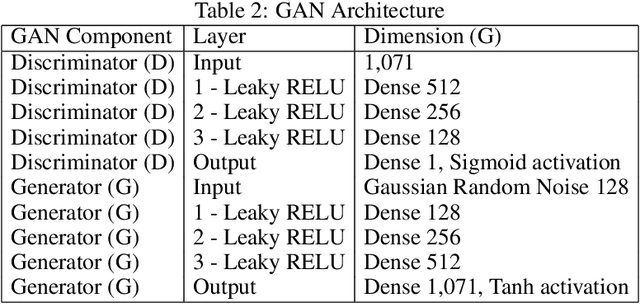
Sensitive medical data is often subject to strict usage constraints. In this paper, we trained a generative adversarial network (GAN) on real-world electronic health records (EHR). It was then used to create a data-set of "fake" patients through synthetic data generation (SDG) to circumvent usage constraints. This real-world data was tabular, binary, intensive care unit (ICU) patient diagnosis data. The entire data-set was split into separate data silos to mimic real-world scenarios where multiple ICU units across different hospitals may have similarly structured data-sets within their own organisations but do not have access to each other's data-sets. We implemented federated learning (FL) to train separate GANs locally at each organisation, using their unique data silo and then combining the GANs into a single central GAN, without any siloed data ever being exposed. This global, central GAN was then used to generate the synthetic patients data-set. We performed an evaluation of these synthetic patients with statistical measures and through a structured review by a group of medical professionals. It was shown that there was no significant reduction in the quality of the synthetic EHR when we moved between training a single central model and training on separate data silos with individual models before combining them into a central model. This was true for both the statistical evaluation (Root Mean Square Error (RMSE) of 0.0154 for single-source vs. RMSE of 0.0169 for dual-source federated) and also for the medical professionals' evaluation (no quality difference between EHR generated from a single source and EHR generated from multiple sources).