 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Estimation Using Round-trip Translation with Sentence Embeddings
Paper and Code
Oct 31, 2021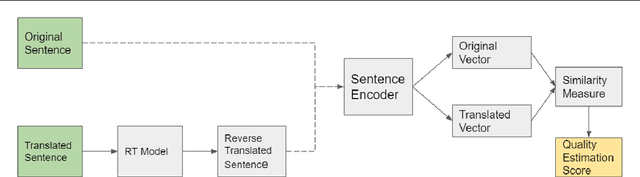
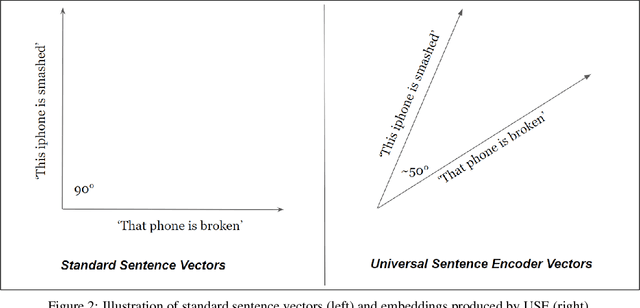

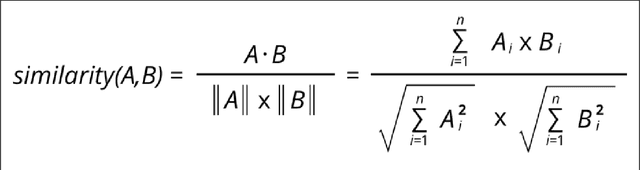
Estimating the quality of machine translation systems has been an ongoing challenge for researchers in this field. Many previous attempts at using round-trip translation as a measure of quality have failed, and there is much disagreement as to whether it can be a viable method of quality estimation. In this paper, we revisit round-trip translation, proposing a system which aims to solve the previous pitfalls found with the approach. Our method makes use of recent advances in language representation learning to more accurately gauge the similarity between the original and round-trip translated sentences. Experiments show that while our approach does not reach the performance of current state of the art methods, it may still be an effective approach for some language pairs.