 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Extraction from Swedish Medical Prescriptions with Sig-Transformer Encoder
Oct 10, 2020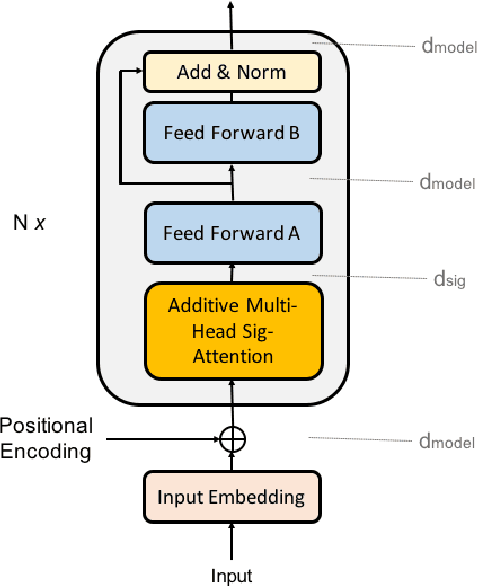
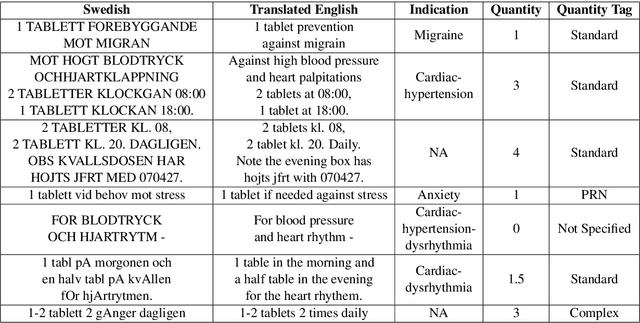
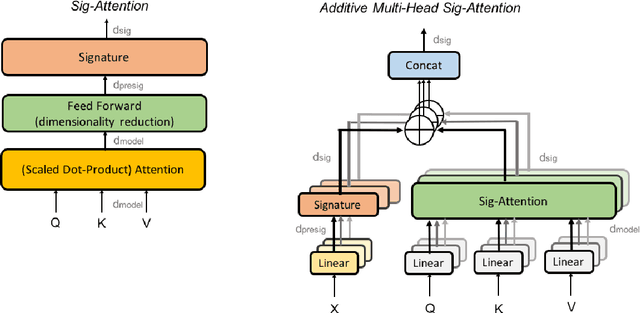
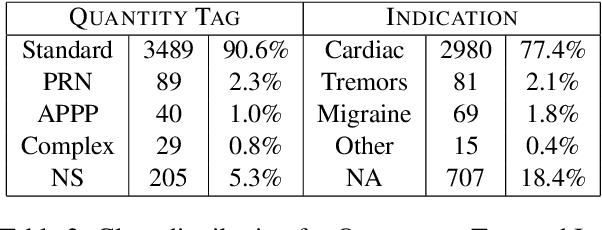
Relying on large pretrained language models such as Bidirectional Encoder Representations from Transformers (BERT) for encoding and adding a simple prediction layer has led to impressive performance in many clinical natural language processing (NLP) tasks. In this work, we present a novel extension to the Transformer architecture, by incorporating signature transform with the self-attention model. This architecture is added between embedding and prediction layers. Experiments on a new Swedish prescription data show the proposed architecture to be superior in two of the three information extraction tasks, comparing to baseline models. Finally, we evaluate two different embedding approaches between applying Multilingual BERT and translating the Swedish text to English then encode with a BERT model pretrained on clinical notes.