 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Sub-skeleton Trajectories for Interpretable Recognition of Sign Language
Feb 03, 2022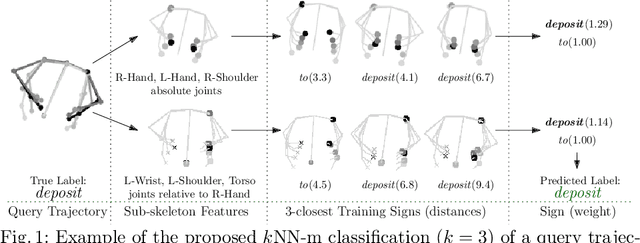
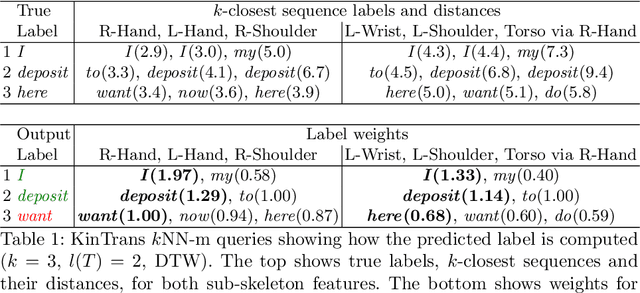
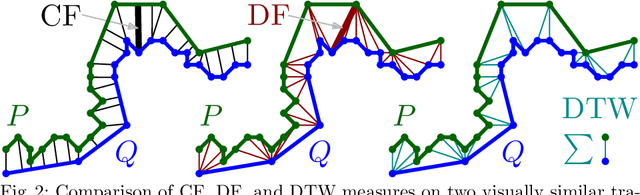
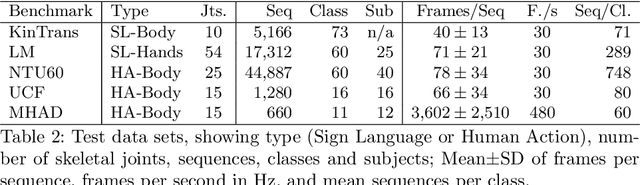
Recent advances in tracking sensors and pose estimation software enable smart systems to use trajectories of skeleton joint locations for supervised learning. We study the problem of accurately recognizing sign language words, which is key to narrowing the communication gap between hard and non-hard of hearing people. Our method explores a geometric feature space that we call `sub-skeleton' aspects of movement. We assess similarity of feature space trajectories using natural, speed invariant distance measures, which enables clear and insightful nearest neighbor classification. The simplicity and scalability of our basic method allows for immediate application in different data domains with little to no parameter tuning. We demonstrate the effectiveness of our basic method, and a boosted variation, with experiments on data from different application domains and tracking technologies. Surprisingly, our simple methods improve sign recognition over recent, state-of-the-art approaches.
A Practical Index Structure Supporting Fréchet Proximity Queries Among Trajectories
May 28, 2020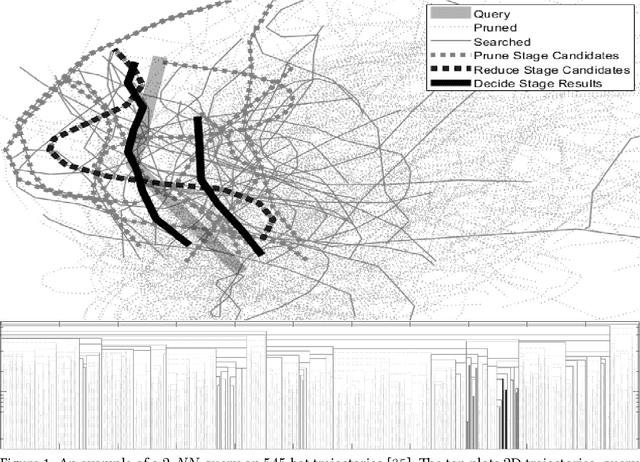

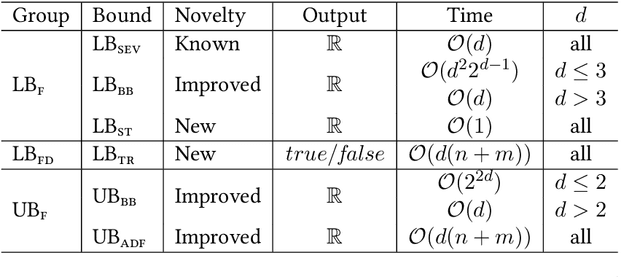
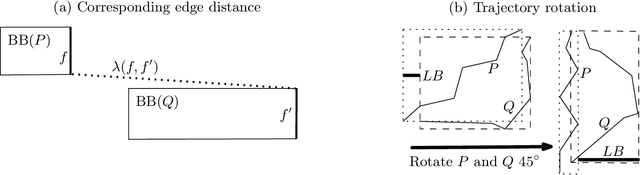
We present a scalable approach for range and $k$ nearest neighbor queries under computationally expensive metrics, like the continuous Fr\'echet distance on trajectory data. Based on clustering for metric indexes, we obtain a dynamic tree structure whose size is linear in the number of trajectories, regardless of the trajectory's individual sizes or the spatial dimension, which allows one to exploit low `intrinsic dimensionality' of data sets for effective search space pruning. Since the distance computation is expensive, generic metric indexing methods are rendered impractical. We present strategies that (i) improve on known upper and lower bound computations, (ii) build cluster trees without any or very few distance calls, and (iii) search using bounds for metric pruning, interval orderings for reduction, and randomized pivoting for reporting the final results. We analyze the efficiency and effectiveness of our methods with extensive experiments on diverse synthetic and real-world data sets. The results show improvement over state-of-the-art methods for exact queries, and even further speed-ups are achieved for queries that may return approximate results. Surprisingly, the majority of exact nearest-neighbor queries on real data sets are answered without any distance computations.