 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiotically-grounded distant viewing of diagrams: insights from two multimodal corpora
Mar 08, 2021



In this article, we bring together theories of multimodal communication and computational methods to study how primary school science diagrams combine multiple expressive resources. We position our work within the field of digital humanities, and show how annotations informed by multimodality research, which target expressive resources and discourse structure, allow imposing structure on the output of computational methods. We illustrate our approach by analysing two multimodal diagram corpora: the first corpus is intended to support research on automatic diagram processing, whereas the second is oriented towards studying diagrams as a mode of communication. Our results show that multimodally-informed annotations can bring out structural patterns in the diagrams, which also extend across diagrams that deal with different topics.
Introducing the diagrammatic mode
Jan 30, 2020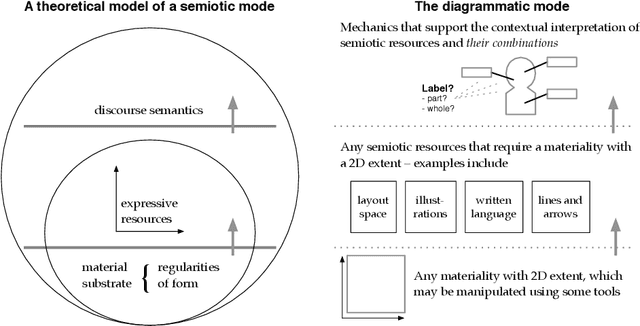



In this article, we propose a multimodal perspective to diagrammatic representations by sketching a description of what may be tentatively termed the diagrammatic mode. We consider diagrammatic representations in the light of contemporary multimodality theory and explicate what enables diagrammatic representations to integrate natural language, various forms of graphics, diagrammatic elements such as arrows, lines and other expressive resources into coherent organisations. We illustrate the proposed approach using two recent diagram corpora and show how a multimodal approach supports the empirical analysis of diagrammatic representations, especially in identifying diagrammatic constituents and describing their interrelations.
AI2D-RST: A multimodal corpus of 1000 primary school science diagrams
Dec 09, 2019

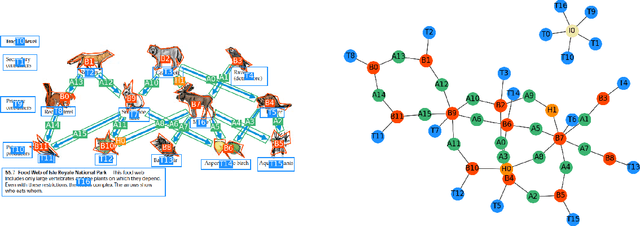

This article introduces AI2D-RST, a multimodal corpus of 1000 English-language diagrams that represent topics in primary school natural science, such as food webs, life cycles, moon phases and human physiology. The corpus is based on the Allen Institute for Artificial Intelligence Diagrams (AI2D) dataset, a collection of diagrams with crowd-sourced descriptions, which was originally developed for computational tasks such as automatic diagram understanding and visual question answering. Building on the segmentation of diagram layouts in AI2D, the AI2D-RST corpus presents a new multi-layer annotation schema that provides a rich description of their multimodal structure. Annotated by trained experts, the layers describe (1) the grouping of diagram elements into perceptual units, (2) the connections set up by diagrammatic elements such as arrows and lines, and (3) the discourse relations between diagram elements, which are described using Rhetorical Structure Theory (RST). Each annotation layer in AI2D-RST is represented using a graph. The corpus is freely available for research and teaching.
Application-driven automatic subgrammar extraction
Nov 19, 1997The space and run-time requirements of broad coverage grammars appear for many applications unreasonably large in relation to the relative simplicity of the task at hand. On the other hand, handcrafted development of application-dependent grammars is in danger of duplicating work which is then difficult to re-use in other contexts of application. To overcome this problem, we present in this paper a procedure for the automatic extraction of application-tuned consistent subgrammars from proved large-scale generation grammars. The procedure has been implemented for large-scale systemic grammars and builds on the formal equivalence between systemic grammars and typed unification based grammars. Its evaluation for the generation of encyclopedia entries is described, and directions of future development, applicability, and extensions are discussed.
Some apparently disjoint aims and requirements for grammar development environments: the case of natural language generation
Nov 19, 1997
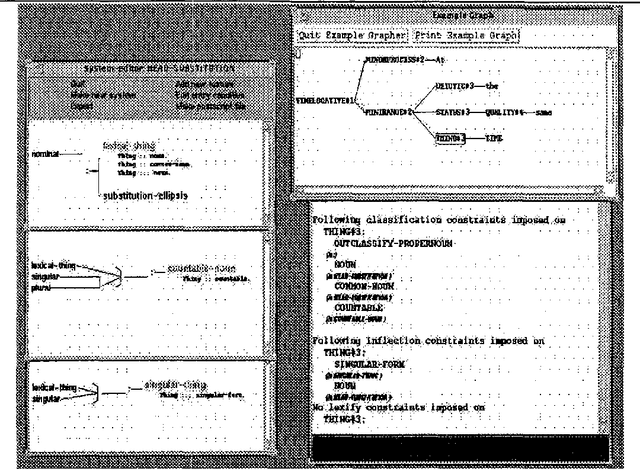
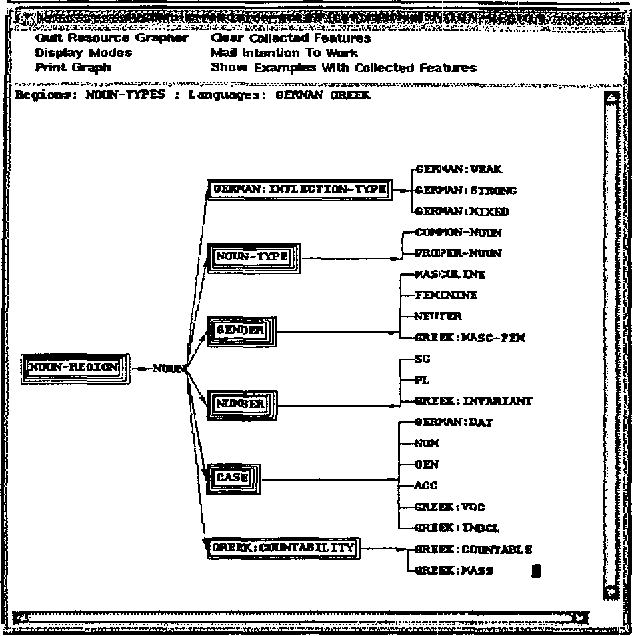
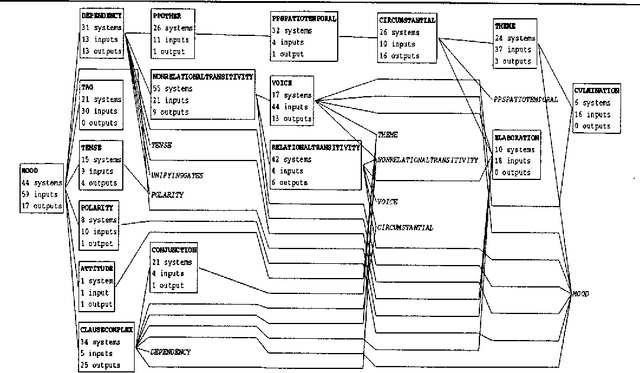
Grammar development environments (GDE's) for analysis and for generation have not yet come together. Despite the fact that analysis-oriented GDE's (such as ALEP) may include some possibility of sentence generation, the development techniques and kinds of resources suggested are apparently not those required for practical, large-scale natural language generation work. Indeed, there is no use of `standard' (i.e., analysis-oriented) GDE's in current projects/applications targetting the generation of fluent, coherent texts. This unsatisfactory situation requires some analysis and explanation, which this paper attempts using as an example an extensive GDE for generation. The support provided for distributed large-scale grammar development, multilinguality, and resource maintenance are discussed and contrasted with analysis-oriented approaches.
Emphatic generation: employing the theory of semantic emphasis for text generation
Apr 25, 1997The paper deals with the problem of text generation and planning approaches making only limited formally specifiable contact with accounts of grammar. We propose an enhancement of a systemically-based generation architecture for German (the KOMET system) by aspects of Kunze's theory of semantic emphasis. Doing this, we gain more control over both concept selection in generation and choice of fine-grained grammatical variation.
The Theoretical Status of Ontologies in Natural Language Processing
Apr 25, 1997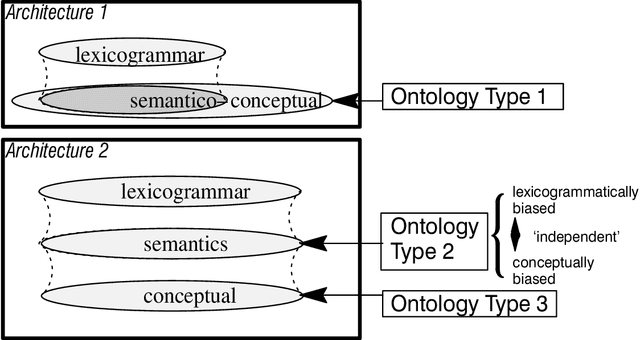


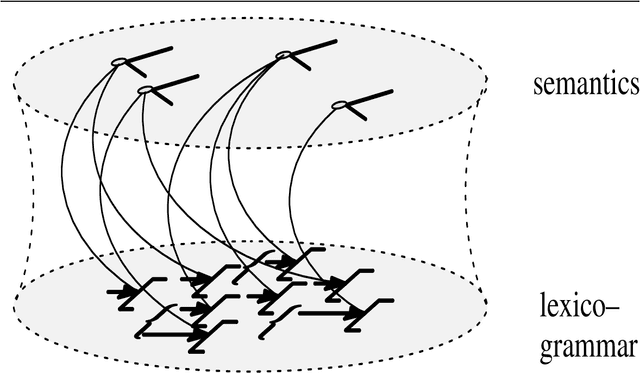
This paper discusses the use of `ontologies' in Natural Language Processing. It classifies various kinds of ontologies that have been employed in NLP and discusses various benefits and problems with those designs. Particular focus is then placed on experiences gained in the use of the Upper Model, a linguistically-motivated `ontology' originally designed for use with the Penman text generation system. Some proposals for further NLP ontology design criteria are then made.