 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen a Relation Tells More Than a Concept: Exploring and Evaluating Classifier Decisions with CoReX
May 02, 2024Explanations for Convolutional Neural Networks (CNNs) based on relevance of input pixels might be too unspecific to evaluate which and how input features impact model decisions. Especially in complex real-world domains like biomedicine, the presence of specific concepts (e.g., a certain type of cell) and of relations between concepts (e.g., one cell type is next to another) might be discriminative between classes (e.g., different types of tissue). Pixel relevance is not expressive enough to convey this type of information. In consequence, model evaluation is limited and relevant aspects present in the data and influencing the model decisions might be overlooked. This work presents a novel method to explain and evaluate CNN models, which uses a concept- and relation-based explainer (CoReX). It explains the predictive behavior of a model on a set of images by masking (ir-)relevant concepts from the decision-making process and by constraining relations in a learned interpretable surrogate model. We test our approach with several image data sets and CNN architectures. Results show that CoReX explanations are faithful to the CNN model in terms of predictive outcomes. We further demonstrate that CoReX is a suitable tool for evaluating CNNs supporting identification and re-classification of incorrect or ambiguous classifications.
Generating Contrastive Explanations for Inductive Logic Programming Based on a Near Miss Approach
Jun 15, 2021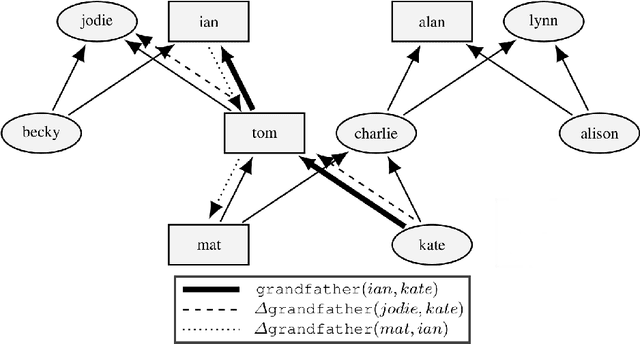


In recent research, human-understandable explanations of machine learning models have received a lot of attention. Often explanations are given in form of model simplifications or visualizations. However, as shown in cognitive science as well as in early AI research, concept understanding can also be improved by the alignment of a given instance for a concept with a similar counterexample. Contrasting a given instance with a structurally similar example which does not belong to the concept highlights what characteristics are necessary for concept membership. Such near misses have been proposed by Winston (1970) as efficient guidance for learning in relational domains. We introduce an explanation generation algorithm for relational concepts learned with Inductive Logic Programming (\textsc{GeNME}). The algorithm identifies near miss examples from a given set of instances and ranks these examples by their degree of closeness to a specific positive instance. A modified rule which covers the near miss but not the original instance is given as an explanation. We illustrate \textsc{GeNME} with the well known family domain consisting of kinship relations, the visual relational Winston arches domain and a real-world domain dealing with file management. We also present a psychological experiment comparing human preferences of rule-based, example-based, and near miss explanations in the family and the arches domains.
Expressive Explanations of DNNs by Combining Concept Analysis with ILP
May 16, 2021



Explainable AI has emerged to be a key component for black-box machine learning approaches in domains with a high demand for reliability or transparency. Examples are medical assistant systems, and applications concerned with the General Data Protection Regulation of the European Union, which features transparency as a cornerstone. Such demands require the ability to audit the rationale behind a classifier's decision. While visualizations are the de facto standard of explanations, they come short in terms of expressiveness in many ways: They cannot distinguish between different attribute manifestations of visual features (e.g. eye open vs. closed), and they cannot accurately describe the influence of absence of, and relations between features. An alternative would be more expressive symbolic surrogate models. However, these require symbolic inputs, which are not readily available in most computer vision tasks. In this paper we investigate how to overcome this: We use inherent features learned by the network to build a global, expressive, verbal explanation of the rationale of a feed-forward convolutional deep neural network (DNN). The semantics of the features are mined by a concept analysis approach trained on a set of human understandable visual concepts. The explanation is found by an Inductive Logic Programming (ILP) method and presented as first-order rules. We show that our explanation is faithful to the original black-box model. The code for our experiments is available at https://github.com/mc-lovin-mlem/concept-embeddings-and-ilp/tree/ki2020.
Effect of Superpixel Aggregation on Explanations in LIME -- A Case Study with Biological Data
Oct 17, 2019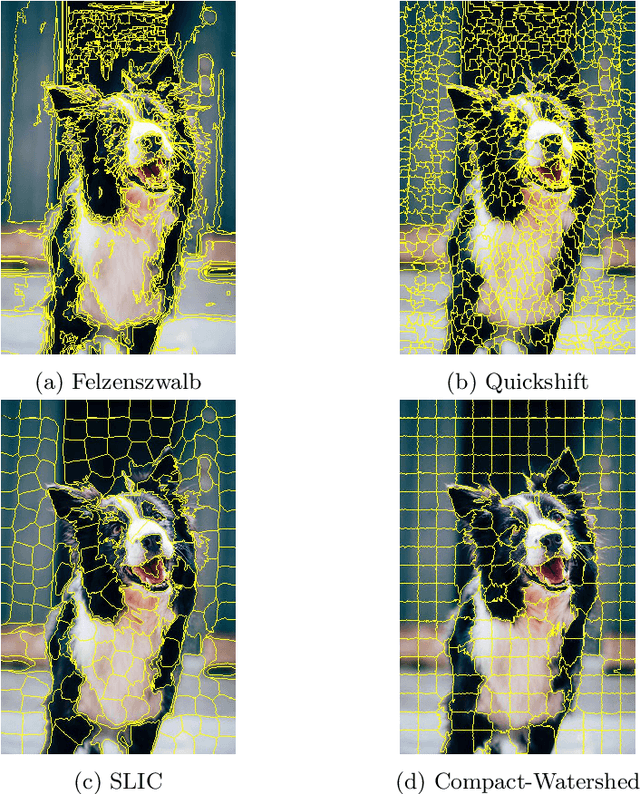
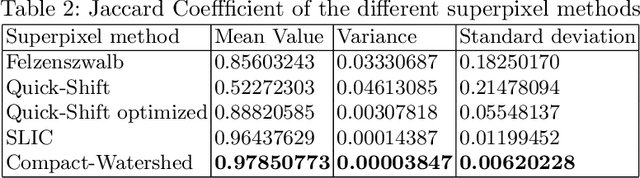

End-to-end learning with deep neural networks, such as convolutional neural networks (CNNs), has been demonstrated to be very successful for different tasks of image classification. To make decisions of black-box approaches transparent, different solutions have been proposed. LIME is an approach to explainable AI relying on segmenting images into superpixels based on the Quick-Shift algorithm. In this paper, we present an explorative study of how different superpixel methods, namely Felzenszwalb, SLIC and Compact-Watershed, impact the generated visual explanations. We compare the resulting relevance areas with the image parts marked by a human reference. Results show that image parts selected as relevant strongly vary depending on the applied method. Quick-Shift resulted in the least and Compact-Watershed in the highest correspondence with the reference relevance areas.
Enriching Visual with Verbal Explanations for Relational Concepts -- Combining LIME with Aleph
Oct 04, 2019
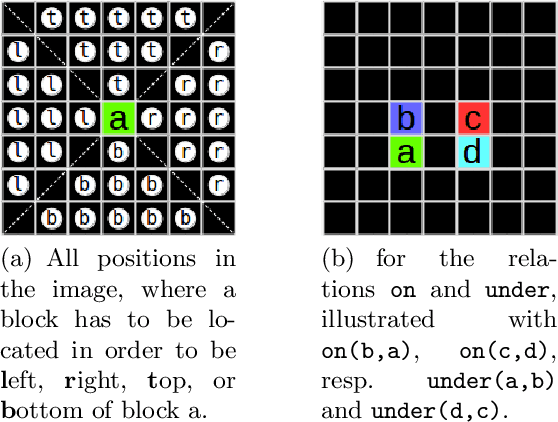
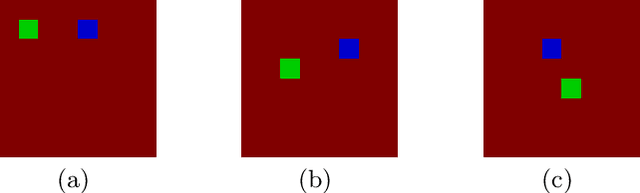

With the increasing number of deep learning applications, there is a growing demand for explanations. Visual explanations provide information about which parts of an image are relevant for a classifier's decision. However, highlighting of image parts (e.g., an eye) cannot capture the relevance of a specific feature value for a class (e.g., that the eye is wide open). Furthermore, highlighting cannot convey whether the classification depends on the mere presence of parts or on a specific spatial relation between them. Consequently, we present an approach that is capable of explaining a classifier's decision in terms of logic rules obtained by the Inductive Logic Programming system Aleph. The examples and the background knowledge needed for Aleph are based on the explanation generation method LIME. We demonstrate our approach with images of a blocksworld domain. First, we show that our approach is capable of identifying a single relation as important explanatory construct. Afterwards, we present the more complex relational concept of towers. Finally, we show how the generated relational rules can be explicitly related with the input image, resulting in richer explanations.