 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys-3D: Physics-Constrained Real-Time Crowd Tracking and Counting on Railway Platforms
Feb 26, 2026Accurate, real-time crowd counting on railway platforms is essential for safety and capacity management. We propose to use a single camera mounted in a train, scanning the platform while arriving. While hardware constraints are simple, counting remains challenging due to dense occlusions, camera motion, and perspective distortions during train arrivals. Most existing tracking-by-detection approaches assume static cameras or ignore physical consistency in motion modeling, leading to unreliable counting under dynamic conditions. We propose a physics-constrained tracking framework that unifies detection, appearance, and 3D motion reasoning in a real-time pipeline. Our approach integrates a transfer-learned YOLOv11m detector with EfficientNet-B0 appearance encoding within DeepSORT, while introducing a physics-constrained Kalman model (Phys-3D) that enforces physically plausible 3D motion dynamics through pinhole geometry. To address counting brittleness under occlusions, we implement a virtual counting band with persistence. On our platform benchmark, MOT-RailwayPlatformCrowdHead Dataset(MOT-RPCH), our method reduces counting error to 2.97%, demonstrating robust performance despite motion and occlusions. Our results show that incorporating first-principles geometry and motion priors enables reliable crowd counting in safety-critical transportation scenarios, facilitating effective train scheduling and platform safety management.
* published at VISAPP 2026
BTSeg: Barlow Twins Regularization for Domain Adaptation in Semantic Segmentation
Aug 31, 2023
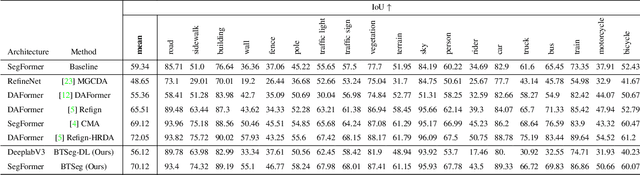


Semantic image segmentation is a critical component in many computer vision systems, such as autonomous driving. In such applications, adverse conditions (heavy rain, night time, snow, extreme lighting) on the one hand pose specific challenges, yet are typically underrepresented in the available datasets. Generating more training data is cumbersome and expensive, and the process itself is error-prone due to the inherent aleatoric uncertainty. To address this challenging problem, we propose BTSeg, which exploits image-level correspondences as weak supervision signal to learn a segmentation model that is agnostic to adverse conditions. To this end, our approach uses the Barlow twins loss from the field of unsupervised learning and treats images taken at the same location but under different adverse conditions as "augmentations" of the same unknown underlying base image. This allows the training of a segmentation model that is robust to appearance changes introduced by different adverse conditions. We evaluate our approach on ACDC and the new challenging ACG benchmark to demonstrate its robustness and generalization capabilities. Our approach performs favorably when compared to the current state-of-the-art methods, while also being simpler to implement and train. The code will be released upon acceptance.
System for 3D Acquisition and 3D Reconstruction using Structured Light for Sewer Line Inspection
Mar 06, 2023The assessment of sewer pipe systems is a highly important, but at the same time cumbersome and error-prone task. We introduce an innovative system based on single-shot structured light modules that facilitates the detection and classification of spatial defects like jutting intrusions, spallings, or misaligned joints. This system creates highly accurate 3D measurements with sub-millimeter resolution of pipe surfaces and fuses them into a holistic 3D model. The benefit of such a holistic 3D model is twofold: on the one hand, it facilitates the accurate manual sewer pipe assessment, on the other, it simplifies the detection of defects in downstream automatic systems as it endows the input with highly accurate depth information. In this work, we provide an extensive overview of the system and give valuable insights into our design choices.
* 10 pages, published at VISAPP 2023, Lisbon, Portugal
From Explanations to Segmentation: Using Explainable AI for Image Segmentation
Feb 01, 2022



The new era of image segmentation leveraging the power of Deep Neural Nets (DNNs) comes with a price tag: to train a neural network for pixel-wise segmentation, a large amount of training samples has to be manually labeled on pixel-precision. In this work, we address this by following an indirect solution. We build upon the advances of the Explainable AI (XAI) community and extract a pixel-wise binary segmentation from the output of the Layer-wise Relevance Propagation (LRP) explaining the decision of a classification network. We show that we achieve similar results compared to an established U-Net segmentation architecture, while the generation of the training data is significantly simplified. The proposed method can be trained in a weakly supervised fashion, as the training samples must be only labeled on image-level, at the same time enabling the output of a segmentation mask. This makes it especially applicable to a wider range of real applications where tedious pixel-level labelling is often not possible.
Automatic Analysis of Sewer Pipes Based on Unrolled Monocular Fisheye Images
Dec 11, 2019
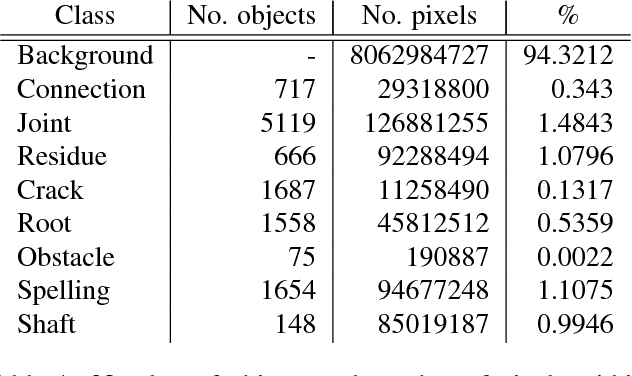
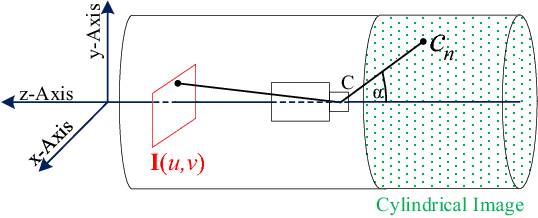
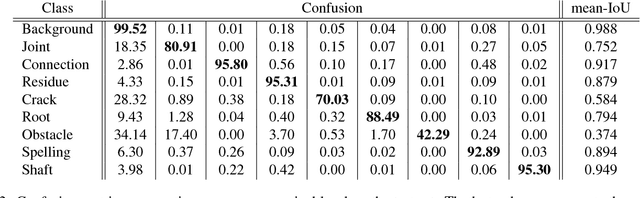
The task of detecting and classifying damages in sewer pipes offers an important application area for computer vision algorithms. This paper describes a system, which is capable of accomplishing this task solely based on low quality and severely compressed fisheye images from a pipe inspection robot. Relying on robust image features, we estimate camera poses, model the image lighting, and exploit this information to generate high quality cylindrical unwraps of the pipes' surfaces.Based on the generated images, we apply semantic labeling based on deep convolutional neural networks to detect and classify defects as well as structural elements.
* Published in: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV)