 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Multimodal Depth Estimation Based on Camera-LiDAR Sensor Fusion
Jul 20, 2023Multi-modal depth estimation is one of the key challenges for endowing autonomous machines with robust robotic perception capabilities. There have been outstanding advances in the development of uni-modal depth estimation techniques based on either monocular cameras, because of their rich resolution, or LiDAR sensors, due to the precise geometric data they provide. However, each of these suffers from some inherent drawbacks, such as high sensitivity to changes in illumination conditions in the case of cameras and limited resolution for the LiDARs. Sensor fusion can be used to combine the merits and compensate for the downsides of these two kinds of sensors. Nevertheless, current fusion methods work at a high level. They process the sensor data streams independently and combine the high-level estimates obtained for each sensor. In this paper, we tackle the problem at a low level, fusing the raw sensor streams, thus obtaining depth estimates which are both dense and precise, and can be used as a unified multi-modal data source for higher level estimation problems. This work proposes a Conditional Random Field model with multiple geometry and appearance potentials. It seamlessly represents the problem of estimating dense depth maps from camera and LiDAR data. The model can be optimized efficiently using the Conjugate Gradient Squared algorithm. The proposed method was evaluated and compared with the state-of-the-art using the commonly used KITTI benchmark dataset.
* 15 pages. arXiv admin note: text overlap with arXiv:1411.6387, arXiv:1702.02706 by other authors
Revisiting Rainbow: Promoting more insightful and inclusive deep reinforcement learning research
Nov 20, 2020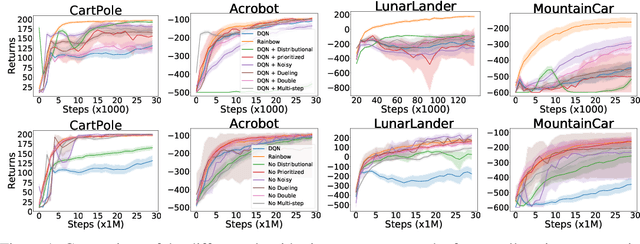

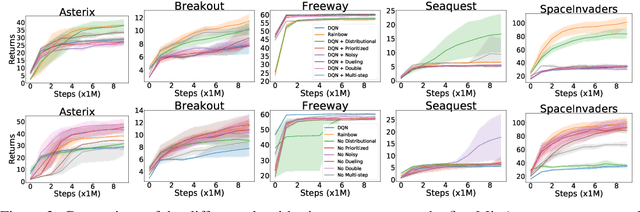

Since the introduction of DQN, a vast majority of reinforcement learning research has focused on reinforcement learning with deep neural networks as function approximators. New methods are typically evaluated on a set of environments that have now become standard, such as Atari 2600 games. While these benchmarks help standardize evaluation, their computational cost has the unfortunate side effect of widening the gap between those with ample access to computational resources, and those without. In this work we argue that, despite the community's emphasis on large-scale environments, the traditional small-scale environments can still yield valuable scientific insights and can help reduce the barriers to entry for underprivileged communities. To substantiate our claims, we empirically revisit the paper which introduced the Rainbow algorithm [Hessel et al., 2018] and present some new insights into the algorithms used by Rainbow.
Exploiting the potential of deep reinforcement learning for classification tasks in high-dimensional and unstructured data
Dec 20, 2019

This paper presents a framework for efficiently learning feature selection policies which use less features to reach a high classification precision on large unstructured data. It uses a Deep Convolutional Autoencoder (DCAE) for learning compact feature spaces, in combination with recently-proposed Reinforcement Learning (RL) algorithms as Double DQN and Retrace.