 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Web Search Dataset for Federated Online Learning to Rank
Aug 17, 2025The centralized collection of search interaction logs for training ranking models raises significant privacy concerns. Federated Online Learning to Rank (FOLTR) offers a privacy-preserving alternative by enabling collaborative model training without sharing raw user data. However, benchmarks in FOLTR are largely based on random partitioning of classical learning-to-rank datasets, simulated user clicks, and the assumption of synchronous client participation. This oversimplifies real-world dynamics and undermines the realism of experimental results. We present AOL4FOLTR, a large-scale web search dataset with 2.6 million queries from 10,000 users. Our dataset addresses key limitations of existing benchmarks by including user identifiers, real click data, and query timestamps, enabling realistic user partitioning, behavior modeling, and asynchronous federated learning scenarios.
De-DSI: Decentralised Differentiable Search Index
Apr 19, 2024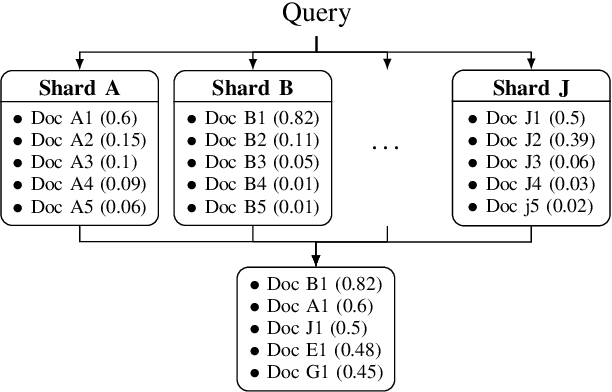
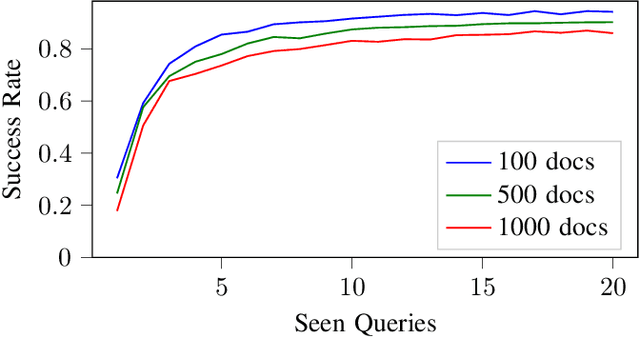
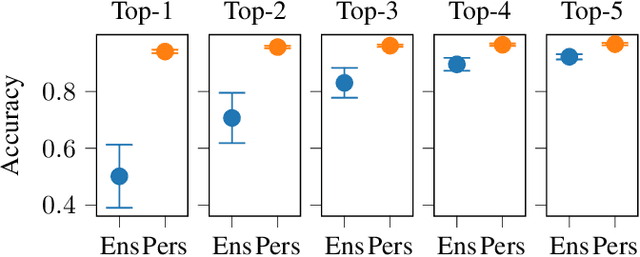
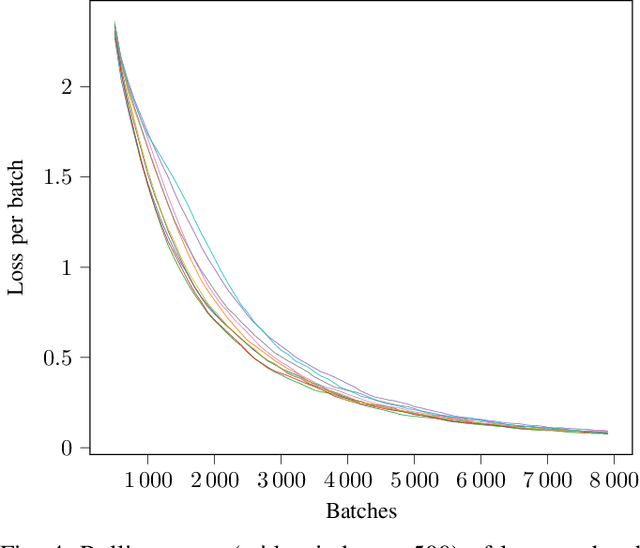
This study introduces De-DSI, a novel framework that fuses large language models (LLMs) with genuine decentralization for information retrieval, particularly employing the differentiable search index (DSI) concept in a decentralized setting. Focused on efficiently connecting novel user queries with document identifiers without direct document access, De-DSI operates solely on query-docid pairs. To enhance scalability, an ensemble of DSI models is introduced, where the dataset is partitioned into smaller shards for individual model training. This approach not only maintains accuracy by reducing the number of data each model needs to handle but also facilitates scalability by aggregating outcomes from multiple models. This aggregation uses a beam search to identify top docids and applies a softmax function for score normalization, selecting documents with the highest scores for retrieval. The decentralized implementation demonstrates that retrieval success is comparable to centralized methods, with the added benefit of the possibility of distributing computational complexity across the network. This setup also allows for the retrieval of multimedia items through magnet links, eliminating the need for platforms or intermediaries.
Augmenting LLMs with Knowledge: A survey on hallucination prevention
Sep 28, 2023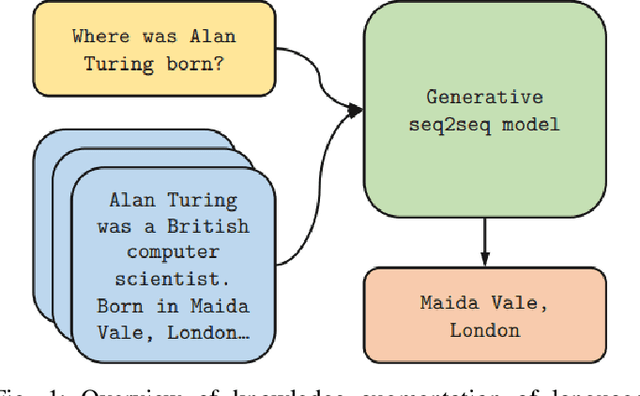


Large pre-trained language models have demonstrated their proficiency in storing factual knowledge within their parameters and achieving remarkable results when fine-tuned for downstream natural language processing tasks. Nonetheless, their capacity to access and manipulate knowledge with precision remains constrained, resulting in performance disparities on knowledge-intensive tasks when compared to task-specific architectures. Additionally, the challenges of providing provenance for model decisions and maintaining up-to-date world knowledge persist as open research frontiers. To address these limitations, the integration of pre-trained models with differentiable access mechanisms to explicit non-parametric memory emerges as a promising solution. This survey delves into the realm of language models (LMs) augmented with the ability to tap into external knowledge sources, including external knowledge bases and search engines. While adhering to the standard objective of predicting missing tokens, these augmented LMs leverage diverse, possibly non-parametric external modules to augment their contextual processing capabilities, departing from the conventional language modeling paradigm. Through an exploration of current advancements in augmenting large language models with knowledge, this work concludes that this emerging research direction holds the potential to address prevalent issues in traditional LMs, such as hallucinations, un-grounded responses, and scalability challenges.
Towards Sybil Resilience in Decentralized Learning
Jun 26, 2023



Federated learning is a privacy-enforcing machine learning technology but suffers from limited scalability. This limitation mostly originates from the internet connection and memory capacity of the central parameter server, and the complexity of the model aggregation function. Decentralized learning has recently been emerging as a promising alternative to federated learning. This novel technology eliminates the need for a central parameter server by decentralizing the model aggregation across all participating nodes. Numerous studies have been conducted on improving the resilience of federated learning against poisoning and Sybil attacks, whereas the resilience of decentralized learning remains largely unstudied. This research gap serves as the main motivator for this study, in which our objective is to improve the Sybil poisoning resilience of decentralized learning. We present SybilWall, an innovative algorithm focused on increasing the resilience of decentralized learning against targeted Sybil poisoning attacks. By combining a Sybil-resistant aggregation function based on similarity between Sybils with a novel probabilistic gossiping mechanism, we establish a new benchmark for scalable, Sybil-resilient decentralized learning. A comprehensive empirical evaluation demonstrated that SybilWall outperforms existing state-of-the-art solutions designed for federated learning scenarios and is the only algorithm to obtain consistent accuracy over a range of adversarial attack scenarios. We also found SybilWall to diminish the utility of creating many Sybils, as our evaluations demonstrate a higher success rate among adversaries employing fewer Sybils. Finally, we suggest a number of possible improvements to SybilWall and highlight promising future research directions.
G-Rank: Unsupervised Continuous Learn-to-Rank for Edge Devices in a P2P Network
Jan 29, 2023Ranking algorithms in traditional search engines are powered by enormous training data sets that are meticulously engineered and curated by a centralized entity. Decentralized peer-to-peer (p2p) networks such as torrenting applications and Web3 protocols deliberately eschew centralized databases and computational architectures when designing services and features. As such, robust search-and-rank algorithms designed for such domains must be engineered specifically for decentralized networks, and must be lightweight enough to operate on consumer-grade personal devices such as a smartphone or laptop computer. We introduce G-Rank, an unsupervised ranking algorithm designed exclusively for decentralized networks. We demonstrate that accurate, relevant ranking results can be achieved in fully decentralized networks without any centralized data aggregation, feature engineering, or model training. Furthermore, we show that such results are obtainable with minimal data preprocessing and computational overhead, and can still return highly relevant results even when a user's device is disconnected from the network. G-Rank is highly modular in design, is not limited to categorical data, and can be implemented in a variety of domains with minimal modification. The results herein show that unsupervised ranking models designed for decentralized p2p networks are not only viable, but worthy of further research.
Bristle: Decentralized Federated Learning in Byzantine, Non-i.i.d. Environments
Oct 21, 2021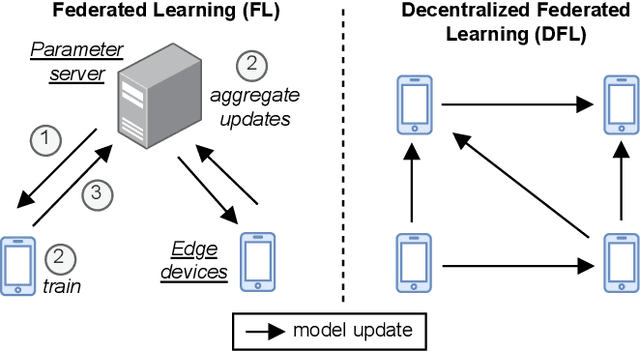
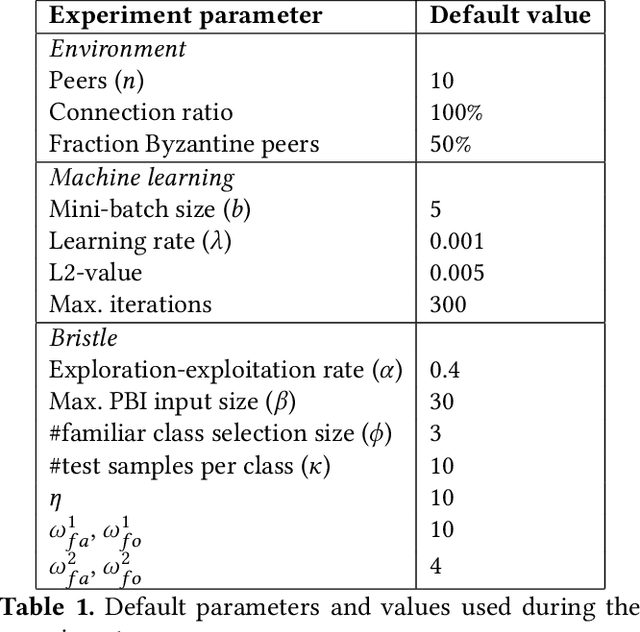
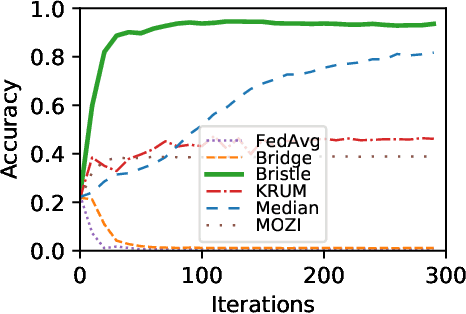
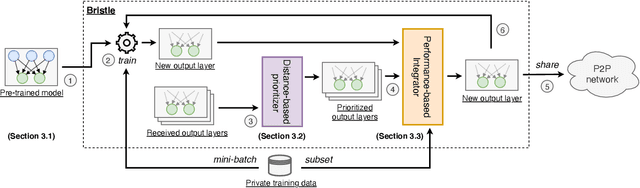
Federated learning (FL) is a privacy-friendly type of machine learning where devices locally train a model on their private data and typically communicate model updates with a server. In decentralized FL (DFL), peers communicate model updates with each other instead. However, DFL is challenging since (1) the training data possessed by different peers is often non-i.i.d. (i.e., distributed differently between the peers) and (2) malicious, or Byzantine, attackers can share arbitrary model updates with other peers to subvert the training process. We address these two challenges and present Bristle, middleware between the learning application and the decentralized network layer. Bristle leverages transfer learning to predetermine and freeze the non-output layers of a neural network, significantly speeding up model training and lowering communication costs. To securely update the output layer with model updates from other peers, we design a fast distance-based prioritizer and a novel performance-based integrator. Their combined effect results in high resilience to Byzantine attackers and the ability to handle non-i.i.d. classes. We empirically show that Bristle converges to a consistent 95% accuracy in Byzantine environments, outperforming all evaluated baselines. In non-Byzantine environments, Bristle requires 83% fewer iterations to achieve 90% accuracy compared to state-of-the-art methods. We show that when the training classes are non-i.i.d., Bristle significantly outperforms the accuracy of the most Byzantine-resilient baselines by 2.3x while reducing communication costs by 90%.