 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBristle: Decentralized Federated Learning in Byzantine, Non-i.i.d. Environments
Paper and Code
Oct 21, 2021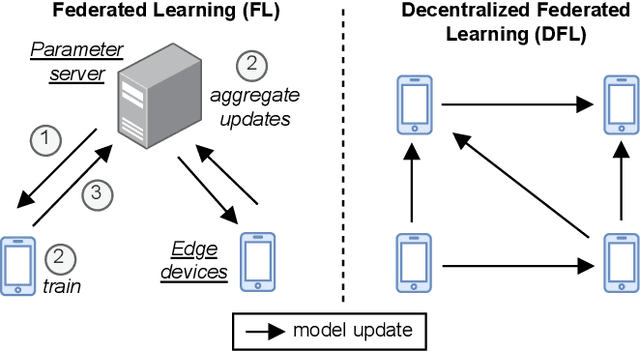
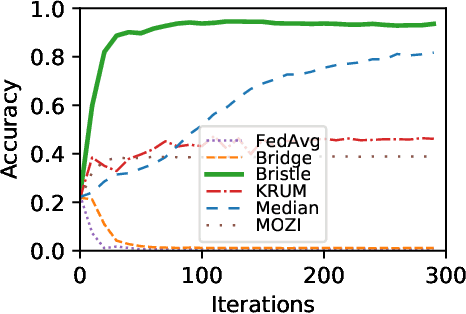
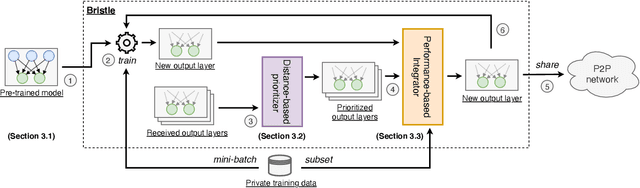
Federated learning (FL) is a privacy-friendly type of machine learning where devices locally train a model on their private data and typically communicate model updates with a server. In decentralized FL (DFL), peers communicate model updates with each other instead. However, DFL is challenging since (1) the training data possessed by different peers is often non-i.i.d. (i.e., distributed differently between the peers) and (2) malicious, or Byzantine, attackers can share arbitrary model updates with other peers to subvert the training process. We address these two challenges and present Bristle, middleware between the learning application and the decentralized network layer. Bristle leverages transfer learning to predetermine and freeze the non-output layers of a neural network, significantly speeding up model training and lowering communication costs. To securely update the output layer with model updates from other peers, we design a fast distance-based prioritizer and a novel performance-based integrator. Their combined effect results in high resilience to Byzantine attackers and the ability to handle non-i.i.d. classes. We empirically show that Bristle converges to a consistent 95% accuracy in Byzantine environments, outperforming all evaluated baselines. In non-Byzantine environments, Bristle requires 83% fewer iterations to achieve 90% accuracy compared to state-of-the-art methods. We show that when the training classes are non-i.i.d., Bristle significantly outperforms the accuracy of the most Byzantine-resilient baselines by 2.3x while reducing communication costs by 90%.