 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Self-Supervised Learning of Multi-Sensor Representations for Embedded Intelligence
Jul 25, 2020

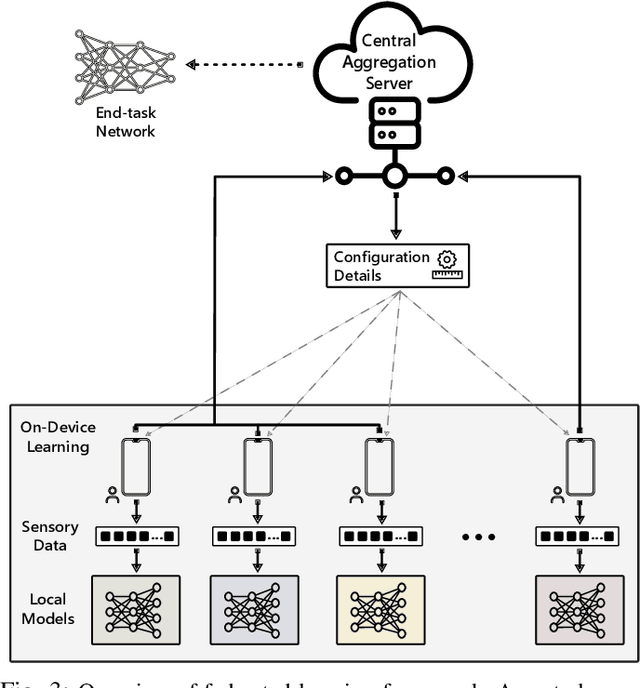

Smartphones, wearables, and Internet of Things (IoT) devices produce a wealth of data that cannot be accumulated in a centralized repository for learning supervised models due to privacy, bandwidth limitations, and the prohibitive cost of annotations. Federated learning provides a compelling framework for learning models from decentralized data, but conventionally, it assumes the availability of labeled samples, whereas on-device data are generally either unlabeled or cannot be annotated readily through user interaction. To address these issues, we propose a self-supervised approach termed \textit{scalogram-signal correspondence learning} based on wavelet transform to learn useful representations from unlabeled sensor inputs, such as electroencephalography, blood volume pulse, accelerometer, and WiFi channel state information. Our auxiliary task requires a deep temporal neural network to determine if a given pair of a signal and its complementary viewpoint (i.e., a scalogram generated with a wavelet transform) align with each other or not through optimizing a contrastive objective. We extensively assess the quality of learned features with our multi-view strategy on diverse public datasets, achieving strong performance in all domains. We demonstrate the effectiveness of representations learned from an unlabeled input collection on downstream tasks with training a linear classifier over pretrained network, usefulness in low-data regime, transfer learning, and cross-validation. Our methodology achieves competitive performance with fully-supervised networks, and it outperforms pre-training with autoencoders in both central and federated contexts. Notably, it improves the generalization in a semi-supervised setting as it reduces the volume of labeled data required through leveraging self-supervised learning.
Multi-task Self-Supervised Learning for Human Activity Detection
Jul 27, 2019



Deep learning methods are successfully used in applications pertaining to ubiquitous computing, health, and well-being. Specifically, the area of human activity recognition (HAR) is primarily transformed by the convolutional and recurrent neural networks, thanks to their ability to learn semantic representations from raw input. However, to extract generalizable features, massive amounts of well-curated data are required, which is a notoriously challenging task; hindered by privacy issues, and annotation costs. Therefore, unsupervised representation learning is of prime importance to leverage the vast amount of unlabeled data produced by smart devices. In this work, we propose a novel self-supervised technique for feature learning from sensory data that does not require access to any form of semantic labels. We learn a multi-task temporal convolutional network to recognize transformations applied on an input signal. By exploiting these transformations, we demonstrate that simple auxiliary tasks of the binary classification result in a strong supervisory signal for extracting useful features for the downstream task. We extensively evaluate the proposed approach on several publicly available datasets for smartphone-based HAR in unsupervised, semi-supervised, and transfer learning settings. Our method achieves performance levels superior to or comparable with fully-supervised networks, and it performs significantly better than autoencoders. Notably, for the semi-supervised case, the self-supervised features substantially boost the detection rate by attaining a kappa score between 0.7-0.8 with only 10 labeled examples per class. We get similar impressive performance even if the features are transferred from a different data source. While this paper focuses on HAR as the application domain, the proposed technique is general and could be applied to a wide variety of problems in other areas.
Learning behavioral context recognition with multi-stream temporal convolutional networks
Aug 27, 2018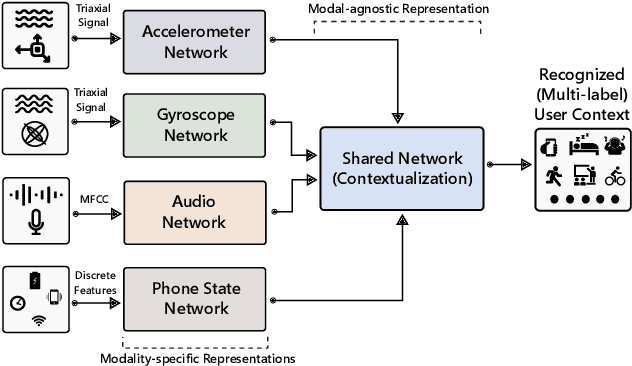


Smart devices of everyday use (such as smartphones and wearables) are increasingly integrated with sensors that provide immense amounts of information about a person's daily life such as behavior and context. The automatic and unobtrusive sensing of behavioral context can help develop solutions for assisted living, fitness tracking, sleep monitoring, and several other fields. Towards addressing this issue, we raise the question: can a machine learn to recognize a diverse set of contexts and activities in a real-life through joint learning from raw multi-modal signals (e.g. accelerometer, gyroscope and audio etc.)? In this paper, we propose a multi-stream temporal convolutional network to address the problem of multi-label behavioral context recognition. A four-stream network architecture handles learning from each modality with a contextualization module which incorporates extracted representations to infer a user's context. Our empirical evaluation suggests that a deep convolutional network trained end-to-end achieves an optimal recognition rate. Furthermore, the presented architecture can be extended to include similar sensors for performance improvements and handles missing modalities through multi-task learning without any manual feature engineering on highly imbalanced and sparsely labeled dataset.