 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Object Detection for Autonomous Vehicles: A Comparative Study of One-Stage and Two-Stage Detectors on Basic Traffic Objects
Jan 30, 2026Object detection is a crucial component in autonomous vehicle systems. It enables the vehicle to perceive and understand its environment by identifying and locating various objects around it. By utilizing advanced imaging and deep learning techniques, autonomous vehicle systems can rapidly and accurately identify objects based on their features. Different deep learning methods vary in their ability to accurately detect and classify objects in autonomous vehicle systems. Selecting the appropriate method significantly impacts system performance, robustness, and efficiency in real-world driving scenarios. While several generic deep learning architectures like YOLO, SSD, and Faster R-CNN have been proposed, guidance on their suitability for specific autonomous driving applications is often limited. The choice of method affects detection accuracy, processing speed, environmental robustness, sensor integration, scalability, and edge case handling. This study provides a comprehensive experimental analysis comparing two prominent object detection models: YOLOv5 (a one-stage detector) and Faster R-CNN (a two-stage detector). Their performance is evaluated on a diverse dataset combining real and synthetic images, considering various metrics including mean Average Precision (mAP), recall, and inference speed. The findings reveal that YOLOv5 demonstrates superior performance in terms of mAP, recall, and training efficiency, particularly as dataset size and image resolution increase. However, Faster R-CNN shows advantages in detecting small, distant objects and performs well in challenging lighting conditions. The models' behavior is also analyzed under different confidence thresholds and in various real-world scenarios, providing insights into their applicability for autonomous driving systems.
Towards Learning Controllable Representations of Physical Systems
Nov 24, 2020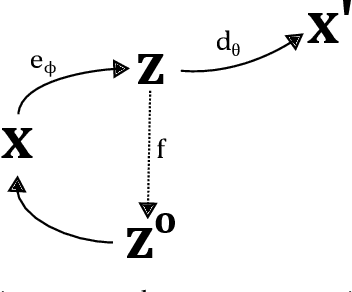


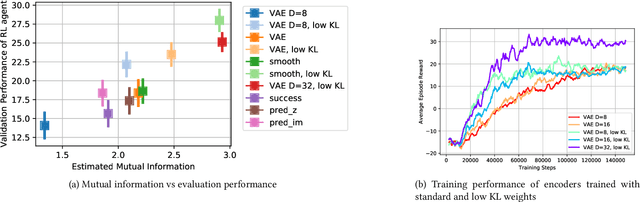
Learned representations of dynamical systems reduce dimensionality, potentially supporting downstream reinforcement learning (RL). However, no established methods predict a representation's suitability for control and evaluation is largely done via downstream RL performance, slowing representation design. Towards a principled evaluation of representations for control, we consider the relationship between the true state and the corresponding representations, proposing that ideally each representation corresponds to a unique true state. This motivates two metrics: temporal smoothness and high mutual information between true state/representation. These metrics are related to established representation objectives, and studied on Lagrangian systems where true state, information requirements, and statistical properties of the state can be formalized for a broad class of systems. These metrics are shown to predict reinforcement learning performance in a simulated peg-in-hole task when comparing variants of autoencoder-based representations.