 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lou Dataset -- Exploring the Impact of Gender-Fair Language in German Text Classification
Sep 26, 2024


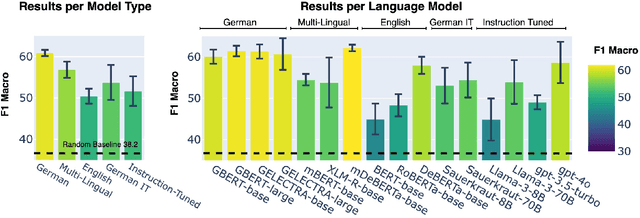
Gender-fair language, an evolving German linguistic variation, fosters inclusion by addressing all genders or using neutral forms. Nevertheless, there is a significant lack of resources to assess the impact of this linguistic shift on classification using language models (LMs), which are probably not trained on such variations. To address this gap, we present Lou, the first dataset featuring high-quality reformulations for German text classification covering seven tasks, like stance detection and toxicity classification. Evaluating 16 mono- and multi-lingual LMs on Lou shows that gender-fair language substantially impacts predictions by flipping labels, reducing certainty, and altering attention patterns. However, existing evaluations remain valid, as LM rankings of original and reformulated instances do not significantly differ. While we offer initial insights on the effect on German text classification, the findings likely apply to other languages, as consistent patterns were observed in multi-lingual and English LMs.