 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization for Markovian Jump Linear Quadratic Control: Gradient-Based Methods and Global Convergence
Nov 24, 2020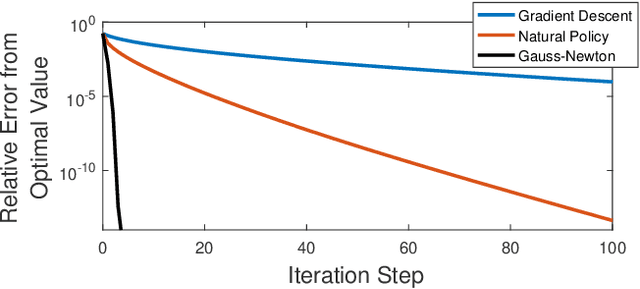
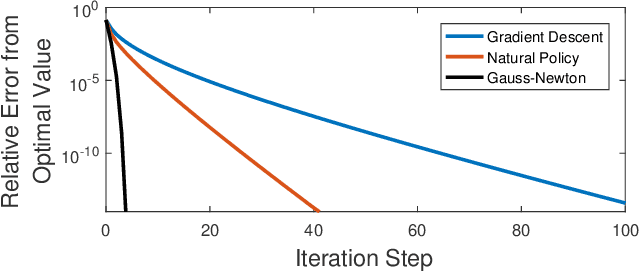
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the global convergence of gradient-based policy optimization methods for quadratic optimal control of discrete-time Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, with static state feedback controllers and quadratic performance costs. Despite the non-convexity of the resultant problem, we are still able to identify several useful properties such as coercivity, gradient dominance, and almost smoothness. Based on these properties, we show global convergence of three types of policy optimization methods: the gradient descent method; the Gauss-Newton method; and the natural policy gradient method. We prove that all three methods converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which is mean-square stabilizing. Some numerical examples are presented to support the theory. This work brings new insights for understanding the performance of policy gradient methods on the Markovian jump linear quadratic control problem.
Policy Learning of MDPs with Mixed Continuous/Discrete Variables: A Case Study on Model-Free Control of Markovian Jump Systems
Jun 04, 2020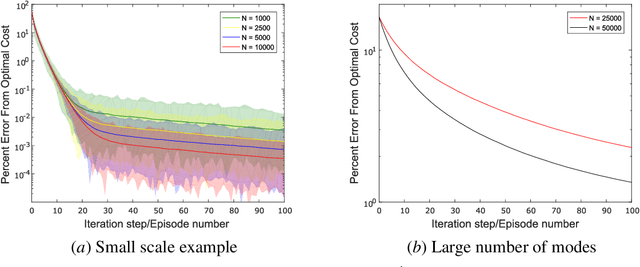
Markovian jump linear systems (MJLS) are an important class of dynamical systems that arise in many control applications. In this paper, we introduce the problem of controlling unknown (discrete-time) MJLS as a new benchmark for policy-based reinforcement learning of Markov decision processes (MDPs) with mixed continuous/discrete state variables. Compared with the traditional linear quadratic regulator (LQR), our proposed problem leads to a special hybrid MDP (with mixed continuous and discrete variables) and poses significant new challenges due to the appearance of an underlying Markov jump parameter governing the mode of the system dynamics. Specifically, the state of a MJLS does not form a Markov chain and hence one cannot study the MJLS control problem as a MDP with solely continuous state variable. However, one can augment the state and the jump parameter to obtain a MDP with a mixed continuous/discrete state space. We discuss how control theory sheds light on the policy parameterization of such hybrid MDPs. Then we modify the widely used natural policy gradient method to directly learn the optimal state feedback control policy for MJLS without identifying either the system dynamics or the transition probability of the switching parameter. We implement the (data-driven) natural policy gradient method on different MJLS examples. Our simulation results suggest that the natural gradient method can efficiently learn the optimal controller for MJLS with unknown dynamics.
Convergence Guarantees of Policy Optimization Methods for Markovian Jump Linear Systems
Feb 10, 2020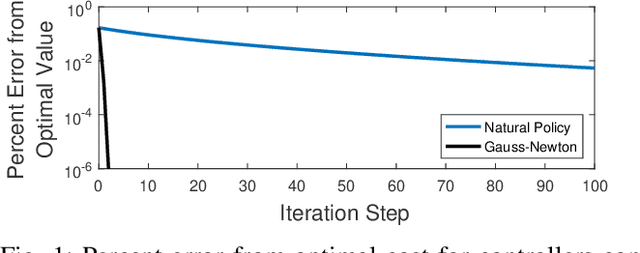
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the convergence of policy optimization for quadratic control of Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, and, in particular, show that despite the non-convexity of the resultant problem the unique stationary point is the global optimal solution. Next, we prove that the Gauss-Newton method and the natural policy gradient method converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which stabilizes the closed-loop dynamics in the mean square sense. We propose a novel Lyapunov argument to fix a key stability issue in the convergence proof. Finally, we present a numerical example to support our theory. Our work brings new insights for understanding the performance of policy learning methods on controlling unknown MJLS.