 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGAS: Automated Evaluation of Retrieval Augmented Generation
Sep 26, 2023We introduce RAGAs (Retrieval Augmented Generation Assessment), a framework for reference-free evaluation of Retrieval Augmented Generation (RAG) pipelines. RAG systems are composed of a retrieval and an LLM based generation module, and provide LLMs with knowledge from a reference textual database, which enables them to act as a natural language layer between a user and textual databases, reducing the risk of hallucinations. Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself. With RAGAs, we put forward a suite of metrics which can be used to evaluate these different dimensions \textit{without having to rely on ground truth human annotations}. We posit that such a framework can crucially contribute to faster evaluation cycles of RAG architectures, which is especially important given the fast adoption of LLMs.
DeepHashing using TripletLoss
Dec 17, 2019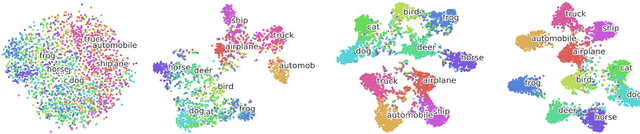


Hashing is one of the most efficient techniques for approximate nearest neighbour search for large scale image retrieval. Most of the techniques are based on hand-engineered features and do not give optimal results all the time. Deep Convolutional Neural Networks have proven to generate very effective representation of images that are used for various computer vision tasks and inspired by this there have been several Deep Hashing models like Wang et al. (2016) have been proposed. These models train on the triplet loss function which can be used to train models with superior representation capabilities. Taking the latest advancements in training using the triplet loss I propose new techniques that help the Deep Hash-ing models train more faster and efficiently. Experiment result1show that using the more efficient techniques for training on the triplet loss, we have obtained a 5%percent improvement in our model compared to the original work of Wang et al.(2016). Using a larger model and more training data we can drastically improve the performance using the techniques we propose