 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Inflation: How Dishonest Providers Can Overcharge for Large Language Model Usage
May 28, 2026Per-token billing is now the standard pricing model for commercial large language models (LLMs), so the honesty of reported token counts directly affects what users pay. We show that this kind of billing is hard to audit by design: providers hide the model, the tokenizer, and the execution to protect their IP, mitigate jailbreaks, and preserve user privacy, which means an auditor can only inspect proofs the provider supplies. The audit therefore reduces to a consistency check on the provider's own reports. We call this a trust paradox: every audit must trust some artifact, but current frameworks trust exactly the ones a provider has the strongest reason to manipulate. We study three recent token auditing frameworks and show that a provider with ordinary commercial capabilities can systematically inflate billed token counts. In the most permissive setting, hidden reasoning usage can be inflated by 1,469% on average without detection. At current frontier reasoning prices, that turns a \$100 honest bill into roughly a \$1,569 bill on the same query. Even when the user can see the full reasoning string, tokenization ambiguity alone still allows 50.85% over-reporting below the detection threshold. These results suggest the problem is not in any specific auditor but in any audit whose evidence comes from the audited party. Restoring honest billing will require verification that ties reported token counts to evidence the provider does not control, such as trusted execution attestation, cryptographic proofs of inference, or third-party re-execution.
ProtDBench: A Unified Benchmark of Protein Binder Design and Evaluation
May 05, 2026Recent advances in de novo protein binder design have enabled increasing experimental validation, yet reported in silico metrics remain difficult to interpret or compare across studies due to non-standardized evaluation protocols. We introduce ProtDBench, a standardized and throughput-aware evaluation framework for protein binder design. ProtDBench defines unified benchmark tasks, evaluation protocols, and success criteria, enabling systematic analysis of how evaluation design influences observed performance. Using a large wet-lab annotated dataset, we analyze commonly used structure prediction models as evaluation verifiers, revealing substantial verifier-dependent bias and limited agreement under identical filtering protocols. We then benchmark representative open-source generative binder design methods across ten diverse protein targets under a fixed evaluation protocol. Beyond per-sequence success rates, ProtDBench incorporates throughput-aware metrics based on a fixed 24-hour budget, as well as cluster-level success criteria to account for structural diversity. Together, these results expose systematic differences induced by filtering rules, success definitions, and throughput-aware evaluation between computational efficiency, success rate, and structural diversity. Overall, ProtDBench provides a fair and reproducible evaluation pipeline that supports systematic and controlled comparison of protein binder design methods under realistic evaluation settings.
HRI Challenges Influencing Low Usage of Robotic Systems in Disaster Response and Rescue Operations
Jan 28, 2024The breakthrough in AI and Machine Learning has brought a new revolution in robotics, resulting in the construction of more sophisticated robotic systems. Not only can these robotic systems benefit all domains, but also can accomplish tasks that seemed to be unimaginable a few years ago. From swarms of autonomous small robots working together to more very heavy and large objects, to seemingly indestructible robots capable of going to the harshest environments, we can see robotic systems designed for every task imaginable. Among them, a key scenario where robotic systems can benefit is in disaster response scenarios and rescue operations. Robotic systems are capable of successfully conducting tasks such as removing heavy materials, utilizing multiple advanced sensors for finding objects of interest, moving through debris and various inhospitable environments, and not the least have flying capabilities. Even with so much potential, we rarely see the utilization of robotic systems in disaster response scenarios and rescue missions. Many factors could be responsible for the low utilization of robotic systems in such scenarios. One of the key factors involve challenges related to Human-Robot Interaction (HRI) issues. Therefore, in this paper, we try to understand the HRI challenges involving the utilization of robotic systems in disaster response and rescue operations. Furthermore, we go through some of the proposed robotic systems designed for disaster response scenarios and identify the HRI challenges of those systems. Finally, we try to address the challenges by introducing ideas from various proposed research works.
Latent Group Structured Multi-task Learning
Nov 24, 2020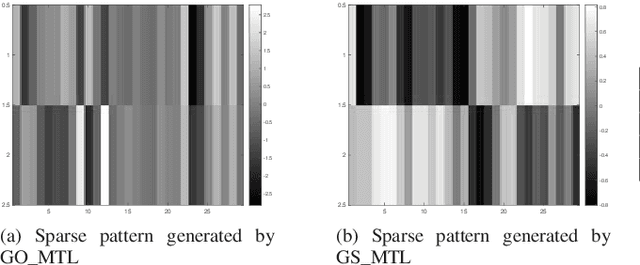
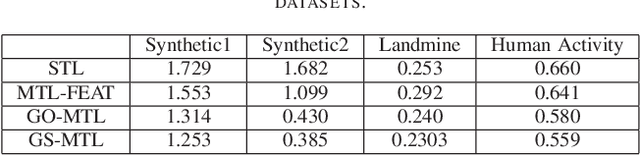
In multi-task learning (MTL), we improve the performance of key machine learning algorithms by training various tasks jointly. When the number of tasks is large, modeling task structure can further refine the task relationship model. For example, often tasks can be grouped based on metadata, or via simple preprocessing steps like K-means. In this paper, we present our group structured latent-space multi-task learning model, which encourages group structured tasks defined by prior information. We use an alternating minimization method to learn the model parameters. Experiments are conducted on both synthetic and real-world datasets, showing competitive performance over single-task learning (where each group is trained separately) and other MTL baselines.