 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropRAG: Guiding Retrieval with Beam Search over Proposition Paths
Apr 25, 2025Retrieval Augmented Generation (RAG) has become the standard non-parametric approach for equipping Large Language Models (LLMs) with up-to-date knowledge and mitigating catastrophic forgetting common in continual learning. However, standard RAG, relying on independent passage retrieval, fails to capture the interconnected nature of human memory crucial for complex reasoning (associativity) and contextual understanding (sense-making). While structured RAG methods like HippoRAG utilize knowledge graphs (KGs) built from triples, the inherent context loss limits fidelity. We introduce PropRAG, a framework leveraging contextually rich propositions and a novel beam search algorithm over proposition paths to explicitly discover multi-step reasoning chains. Crucially, PropRAG's online retrieval process operates entirely without invoking generative LLMs, relying instead on efficient graph traversal and pre-computed embeddings. This avoids online LLM inference costs and potential inconsistencies during evidence gathering. LLMs are used effectively offline for high-quality proposition extraction and post-retrieval for answer generation. PropRAG achieves state-of-the-art zero-shot Recall@5 results on PopQA (55.3%), 2Wiki (93.7%), HotpotQA (97.0%), and MuSiQue (77.3%), alongside top F1 scores (e.g., 52.4% on MuSiQue). By improving evidence retrieval through richer representation and explicit, LLM-free online path finding, PropRAG advances non-parametric continual learning.
LLMs can realize combinatorial creativity: generating creative ideas via LLMs for scientific research
Dec 18, 2024



Scientific idea generation has been extensively studied in creativity theory and computational creativity research, providing valuable frameworks for understanding and implementing creative processes. However, recent work using Large Language Models (LLMs) for research idea generation often overlooks these theoretical foundations. We present a framework that explicitly implements combinatorial creativity theory using LLMs, featuring a generalization-level retrieval system for cross-domain knowledge discovery and a structured combinatorial process for idea generation. The retrieval system maps concepts across different abstraction levels to enable meaningful connections between disparate domains, while the combinatorial process systematically analyzes and recombines components to generate novel solutions. Experiments on the OAG-Bench dataset demonstrate our framework's effectiveness, consistently outperforming baseline approaches in generating ideas that align with real research developments (improving similarity scores by 7\%-10\% across multiple metrics). Our results provide strong evidence that LLMs can effectively realize combinatorial creativity when guided by appropriate theoretical frameworks, contributing both to practical advancement of AI-assisted research and theoretical understanding of machine creativity.
CoVA: Context-aware Visual Attention for Webpage Information Extraction
Oct 24, 2021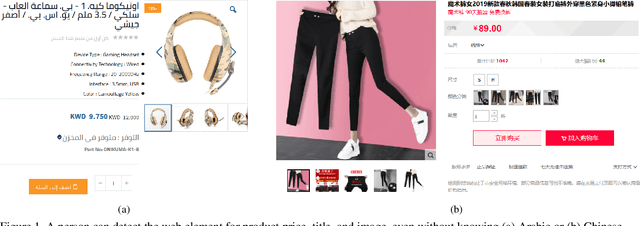
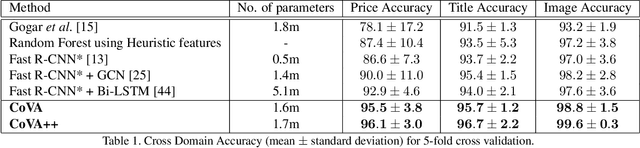
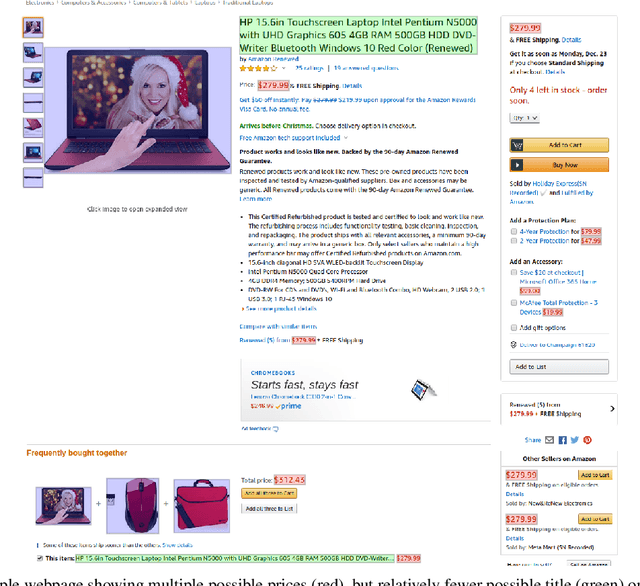
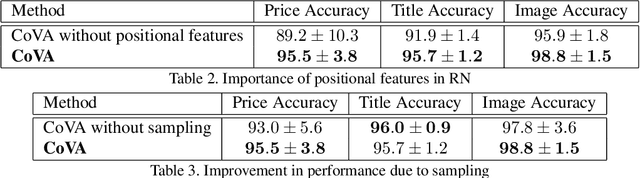
Webpage information extraction (WIE) is an important step to create knowledge bases. For this, classical WIE methods leverage the Document Object Model (DOM) tree of a website. However, use of the DOM tree poses significant challenges as context and appearance are encoded in an abstract manner. To address this challenge we propose to reformulate WIE as a context-aware Webpage Object Detection task. Specifically, we develop a Context-aware Visual Attention-based (CoVA) detection pipeline which combines appearance features with syntactical structure from the DOM tree. To study the approach we collect a new large-scale dataset of e-commerce websites for which we manually annotate every web element with four labels: product price, product title, product image and background. On this dataset we show that the proposed CoVA approach is a new challenging baseline which improves upon prior state-of-the-art methods.