 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-Weighted Topic Model For Large-scale Semi-Structured Documents
Jul 30, 2015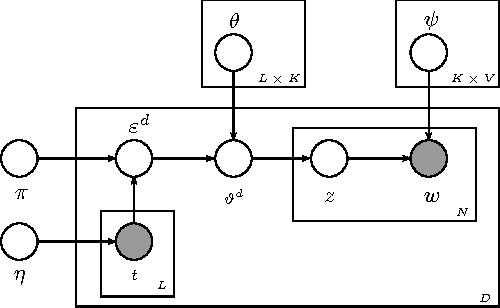


To date, there have been massive Semi-Structured Documents (SSDs) during the evolution of the Internet. These SSDs contain both unstructured features (e.g., plain text) and metadata (e.g., tags). Most previous works focused on modeling the unstructured text, and recently, some other methods have been proposed to model the unstructured text with specific tags. To build a general model for SSDs remains an important problem in terms of both model fitness and efficiency. We propose a novel method to model the SSDs by a so-called Tag-Weighted Topic Model (TWTM). TWTM is a framework that leverages both the tags and words information, not only to learn the document-topic and topic-word distributions, but also to infer the tag-topic distributions for text mining tasks. We present an efficient variational inference method with an EM algorithm for estimating the model parameters. Meanwhile, we propose three large-scale solutions for our model under the MapReduce distributed computing platform for modeling large-scale SSDs. The experimental results show the effectiveness, efficiency and the robustness by comparing our model with the state-of-the-art methods in document modeling, tags prediction and text classification. We also show the performance of the three distributed solutions in terms of time and accuracy on document modeling.