 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal SwinMAE: A Swin Transformer based Multiscale Representation Learner for Temporal Satellite Imagery
May 03, 2024



Currently, the foundation models represented by large language models have made dramatic progress and are used in a very wide range of domains including 2D and 3D vision. As one of the important application domains of foundation models, earth observation has attracted attention and various approaches have been developed. When considering earth observation as a single image capture, earth observation imagery can be processed as an image with three or more channels, and when it comes with multiple image captures of different timestamps at one location, the temporal observation can be considered as a set of continuous image resembling video frames or medical SCAN slices. This paper presents Spatio-Temporal SwinMAE (ST-SwinMAE), an architecture which particularly focuses on representation learning for spatio-temporal image processing. Specifically, it uses a hierarchical Masked Auto-encoder (MAE) with Video Swin Transformer blocks. With the architecture, we present a pretrained model named Degas 100M as a geospatial foundation model. Also, we propose an approach for transfer learning with Degas 100M, which both pretrained encoder and decoder of MAE are utilized with skip connections added between them to achieve multi-scale information communication, forms an architecture named Spatio-Temporal SwinUNet (ST-SwinUNet). Our approach shows significant improvements of performance over existing state-of-the-art of foundation models. Specifically, for transfer learning of the land cover downstream task on the PhilEO Bench dataset, it shows 10.4\% higher accuracy compared with other geospatial foundation models on average.
Understanding the One-Pixel Attack: Propagation Maps and Locality Analysis
Feb 08, 2019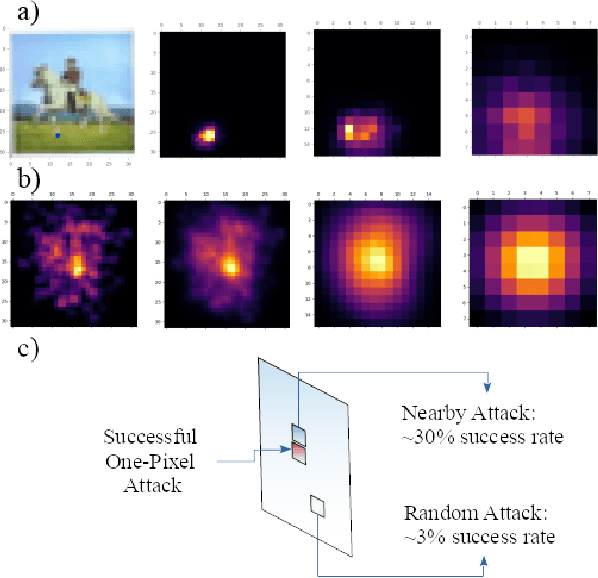

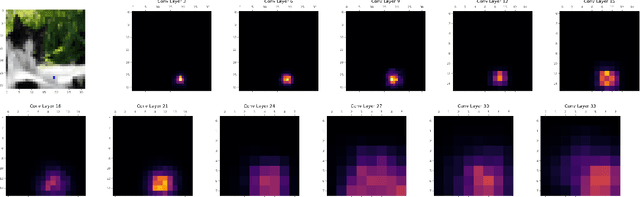
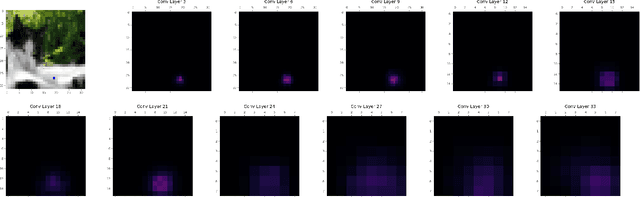
Deep neural networks were shown to be vulnerable to single pixel modifications. However, the reason behind such phenomena has never been elucidated. Here, we propose Propagation Maps which show the influence of the perturbation in each layer of the network. Propagation Maps reveal that even in extremely deep networks such as Resnet, modification in one pixel easily propagates until the last layer. In fact, this initial local perturbation is also shown to spread becoming a global one and reaching absolute difference values that are close to the maximum value of the original feature maps in a given layer. Moreover, we do a locality analysis in which we demonstrate that nearby pixels of the perturbed one in the one-pixel attack tend to share the same vulnerability, revealing that the main vulnerability lies in neither neurons nor pixels but receptive fields. Hopefully, the analysis conducted in this work together with a new technique called propagation maps shall shed light into the inner workings of other adversarial samples and be the basis of new defense systems to come.
Attacking Convolutional Neural Network using Differential Evolution
Apr 19, 2018
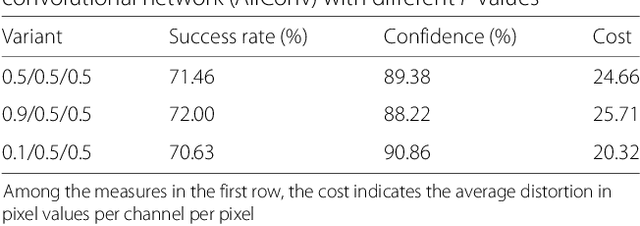

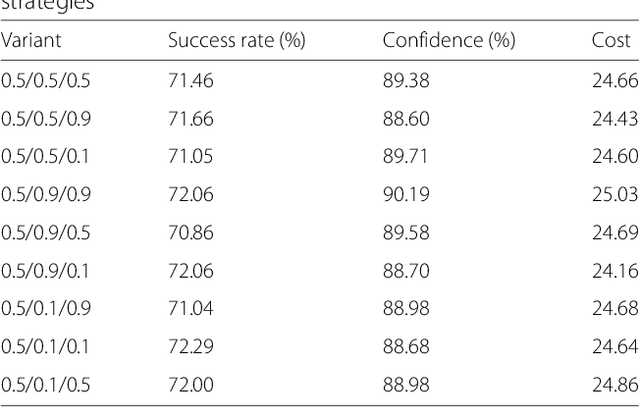
The output of Convolutional Neural Networks (CNN) has been shown to be discontinuous which can make the CNN image classifier vulnerable to small well-tuned artificial perturbations. That is, images modified by adding such perturbations(i.e. adversarial perturbations) that make little difference to human eyes, can completely alter the CNN classification results. In this paper, we propose a practical attack using differential evolution(DE) for generating effective adversarial perturbations. We comprehensively evaluate the effectiveness of different types of DEs for conducting the attack on different network structures. The proposed method is a black-box attack which only requires the miracle feedback of the target CNN systems. The results show that under strict constraints which simultaneously control the number of pixels changed and overall perturbation strength, attacking can achieve 72.29%, 78.24% and 61.28% non-targeted attack success rates, with 88.68%, 99.85% and 73.07% confidence on average, on three common types of CNNs. The attack only requires modifying 5 pixels with 20.44, 14.76 and 22.98 pixel values distortion. Thus, the result shows that the current DNNs are also vulnerable to such simpler black-box attacks even under very limited attack conditions.
One pixel attack for fooling deep neural networks
Feb 22, 2018
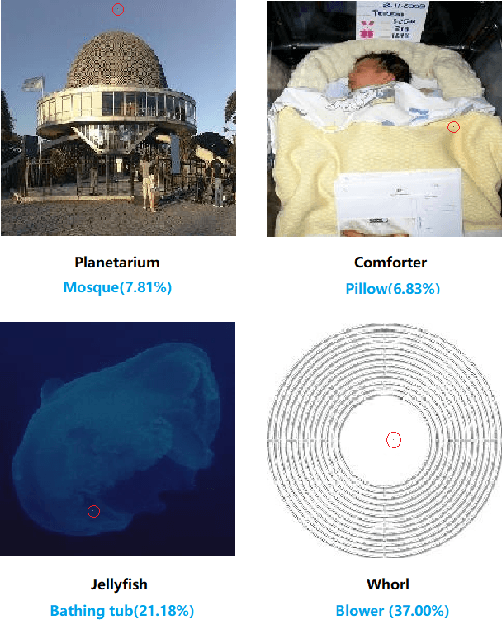

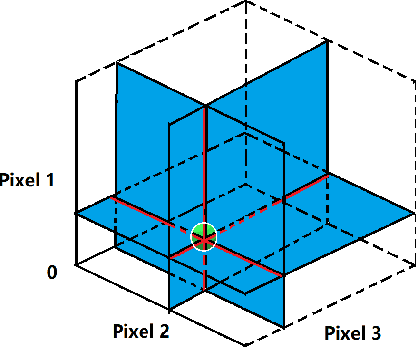
Recent research has revealed that the output of Deep Neural Networks (DNN) can be easily altered by adding relatively small perturbations to the input vector. In this paper, we analyze an attack in an extremely limited scenario where only one pixel can be modified. For that we propose a novel method for generating one-pixel adversarial perturbations based on differential evolution. It requires less adversarial information and can fool more types of networks. The results show that 70.97% of the natural images can be perturbed to at least one target class by modifying just one pixel with 97.47% confidence on average. Thus, the proposed attack explores a different take on adversarial machine learning in an extreme limited scenario, showing that current DNNs are also vulnerable to such low dimension attacks.
Lightweight Classification of IoT Malware based on Image Recognition
Feb 11, 2018



The Internet of Things (IoT) is an extension of the traditional Internet, which allows a very large number of smart devices, such as home appliances, network cameras, sensors and controllers to connect to one another to share information and improve user experiences. Current IoT devices are typically micro-computers for domain-specific computations rather than traditional functionspecific embedded devices. Therefore, many existing attacks, targeted at traditional computers connected to the Internet, may also be directed at IoT devices. For example, DDoS attacks have become very common in IoT environments, as these environments currently lack basic security monitoring and protection mechanisms, as shown by the recent Mirai and Brickerbot IoT botnets. In this paper, we propose a novel light-weight approach for detecting DDos malware in IoT environments.We firstly extract one-channel gray-scale images converted from binaries, and then utilize a lightweight convolutional neural network for classifying IoT malware families. The experimental results show that the proposed system can achieve 94.0% accuracy for the classification of goodware and DDoS malware, and 81.8% accuracy for the classification of goodware and two main malware families.