 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Video Anomaly Detection Model with Weak Supervision and Adaptive Instance Selection
Oct 09, 2023



Video anomaly detection is to determine whether there are any abnormal events, behaviors or objects in a given video, which enables effective and intelligent public safety management. As video anomaly labeling is both time-consuming and expensive, most existing works employ unsupervised or weakly supervised learning methods. This paper focuses on weakly supervised video anomaly detection, in which the training videos are labeled whether or not they contain any anomalies, but there is no information about which frames the anomalies are located. However, the uncertainty of weakly labeled data and the large model size prevent existing methods from wide deployment in real scenarios, especially the resource-limit situations such as edge-computing. In this paper, we develop a lightweight video anomaly detection model. On the one hand, we propose an adaptive instance selection strategy, which is based on the model's current status to select confident instances, thereby mitigating the uncertainty of weakly labeled data and subsequently promoting the model's performance. On the other hand, we design a lightweight multi-level temporal correlation attention module and an hourglass-shaped fully connected layer to construct the model, which can reduce the model parameters to only 0.56\% of the existing methods (e.g. RTFM). Our extensive experiments on two public datasets UCF-Crime and ShanghaiTech show that our model can achieve comparable or even superior AUC score compared to the state-of-the-art methods, with a significantly reduced number of model parameters.
Hierarchical Few-Shot Object Detection: Problem, Benchmark and Method
Oct 08, 2022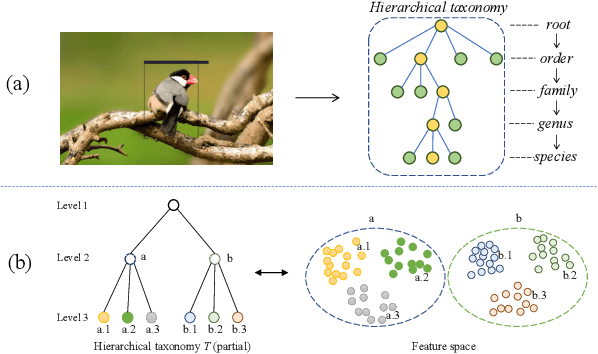

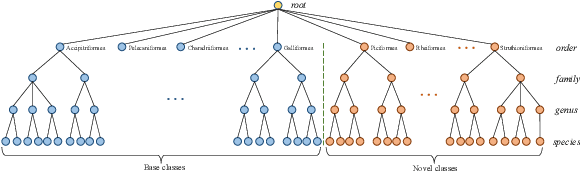

Few-shot object detection (FSOD) is to detect objects with a few examples. However, existing FSOD methods do not consider hierarchical fine-grained category structures of objects that exist widely in real life. For example, animals are taxonomically classified into orders, families, genera and species etc. In this paper, we propose and solve a new problem called hierarchical few-shot object detection (Hi-FSOD), which aims to detect objects with hierarchical categories in the FSOD paradigm. To this end, on the one hand, we build the first large-scale and high-quality Hi-FSOD benchmark dataset HiFSOD-Bird, which contains 176,350 wild-bird images falling to 1,432 categories. All the categories are organized into a 4-level taxonomy, consisting of 32 orders, 132 families, 572 genera and 1,432 species. On the other hand, we propose the first Hi-FSOD method HiCLPL, where a hierarchical contrastive learning approach is developed to constrain the feature space so that the feature distribution of objects is consistent with the hierarchical taxonomy and the model's generalization power is strengthened. Meanwhile, a probabilistic loss is designed to enable the child nodes to correct the classification errors of their parent nodes in the taxonomy. Extensive experiments on the benchmark dataset HiFSOD-Bird show that our method HiCLPL outperforms the existing FSOD methods.