 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS@GT at CheckThat! 2025: A Simple Retrieval-First, LLM-Backed Framework for Claim Normalization
Aug 24, 2025Claim normalization is an integral part of any automatic fact-check verification system. It parses the typically noisy claim data, such as social media posts into normalized claims, which are then fed into downstream veracity classification tasks. The CheckThat! 2025 Task 2 focuses specifically on claim normalization and spans 20 languages under monolingual and zero-shot conditions. Our proposed solution consists of a lightweight \emph{retrieval-first, LLM-backed} pipeline, in which we either dynamically prompt a GPT-4o-mini with in-context examples, or retrieve the closest normalization from the train dataset directly. On the official test set, the system ranks near the top for most monolingual tracks, achieving first place in 7 out of of the 13 languages. In contrast, the system underperforms in the zero-shot setting, highlighting the limitation of the proposed solution.
Comprehensive Modeling Approaches for Forecasting Bitcoin Transaction Fees: A Comparative Study
Feb 03, 2025Transaction fee prediction in Bitcoin's ecosystem represents a crucial challenge affecting both user costs and miner revenue optimization. This study presents a systematic evaluation of six predictive models for forecasting Bitcoin transaction fees across a 24-hour horizon (144 blocks): SARIMAX, Prophet, Time2Vec, Time2Vec with Attention, a Hybrid model combining SARIMAX with Gradient Boosting, and the Temporal Fusion Transformer (TFT). Our approach integrates comprehensive feature engineering spanning mempool metrics, network parameters, and historical fee patterns to capture the multifaceted dynamics of fee behavior. Through rigorous 5-fold cross-validation and independent testing, our analysis reveals that traditional statistical approaches outperform more complex deep learning architectures. The SARIMAX model achieves superior accuracy on the independent test set, while Prophet demonstrates strong performance during cross-validation. Notably, sophisticated deep learning models like Time2Vec and TFT show comparatively lower predictive power despite their architectural complexity. This performance disparity likely stems from the relatively constrained training dataset of 91 days, suggesting that deep learning models may achieve enhanced results with extended historical data. These findings offer significant practical implications for cryptocurrency stakeholders, providing empirically-validated guidance for fee-sensitive decision making while illuminating critical considerations in model selection based on data constraints. The study establishes a foundation for advanced fee prediction while highlighting the current advantages of traditional statistical methods in this domain.
AlgoRxplorers | Precision in Mutation -- Enhancing Drug Design with Advanced Protein Stability Prediction Tools
Jan 13, 2025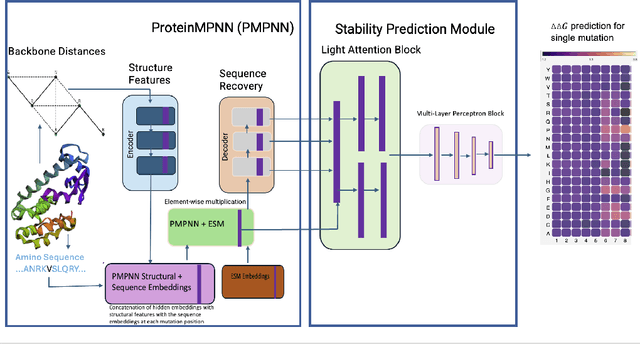


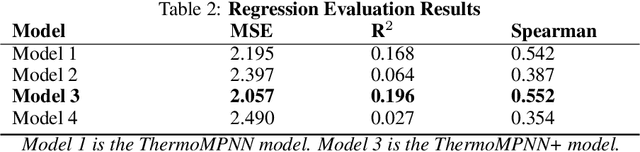
Predicting the impact of single-point amino acid mutations on protein stability is essential for understanding disease mechanisms and advancing drug development. Protein stability, quantified by changes in Gibbs free energy ($\Delta\Delta G$), is influenced by these mutations. However, the scarcity of data and the complexity of model interpretation pose challenges in accurately predicting stability changes. This study proposes the application of deep neural networks, leveraging transfer learning and fusing complementary information from different models, to create a feature-rich representation of the protein stability landscape. We developed four models, with our third model, ThermoMPNN+, demonstrating the best performance in predicting $\Delta\Delta G$ values. This approach, which integrates diverse feature sets and embeddings through latent transfusion techniques, aims to refine $\Delta\Delta G$ predictions and contribute to a deeper understanding of protein dynamics, potentially leading to advancements in disease research and drug discovery.
Fine-Tuning Stable Diffusion XL for Stylistic Icon Generation: A Comparison of Caption Size
Jul 11, 2024



In this paper, we show different fine-tuning methods for Stable Diffusion XL; this includes inference steps, and caption customization for each image to align with generating images in the style of a commercial 2D icon training set. We also show how important it is to properly define what "high-quality" really is especially for a commercial-use environment. As generative AI models continue to gain widespread acceptance and usage, there emerge many different ways to optimize and evaluate them for various applications. Specifically text-to-image models, such as Stable Diffusion XL and DALL-E 3 require distinct evaluation practices to effectively generate high-quality icons according to a specific style. Although some images that are generated based on a certain style may have a lower FID score (better), we show how this is not absolute in and of itself even for rasterized icons. While FID scores reflect the similarity of generated images to the overall training set, CLIP scores measure the alignment between generated images and their textual descriptions. We show how FID scores miss significant aspects, such as the minority of pixel differences that matter most in an icon, while CLIP scores result in misjudging the quality of icons. The CLIP model's understanding of "similarity" is shaped by its own training data; which does not account for feature variation in our style of choice. Our findings highlight the need for specialized evaluation metrics and fine-tuning approaches when generating high-quality commercial icons, potentially leading to more effective and tailored applications of text-to-image models in professional design contexts.
Deep Image-to-Recipe Translation
Jul 01, 2024



The modern saying, "You Are What You Eat" resonates on a profound level, reflecting the intricate connection between our identities and the food we consume. Our project, Deep Image-to-Recipe Translation, is an intersection of computer vision and natural language generation that aims to bridge the gap between cherished food memories and the art of culinary creation. Our primary objective involves predicting ingredients from a given food image. For this task, we first develop a custom convolutional network and then compare its performance to a model that leverages transfer learning. We pursue an additional goal of generating a comprehensive set of recipe steps from a list of ingredients. We frame this process as a sequence-to-sequence task and develop a recurrent neural network that utilizes pre-trained word embeddings. We address several challenges of deep learning including imbalanced datasets, data cleaning, overfitting, and hyperparameter selection. Our approach emphasizes the importance of metrics such as Intersection over Union (IoU) and F1 score in scenarios where accuracy alone might be misleading. For our recipe prediction model, we employ perplexity, a commonly used and important metric for language models. We find that transfer learning via pre-trained ResNet-50 weights and GloVe embeddings provide an exceptional boost to model performance, especially when considering training resource constraints. Although we have made progress on the image-to-recipe translation, there is an opportunity for future exploration with advancements in model architectures, dataset scalability, and enhanced user interaction.