 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFRC: A Unified Framework for Reliable COVID-19 Detection on Crowdsourced Cough Audio
Apr 16, 2022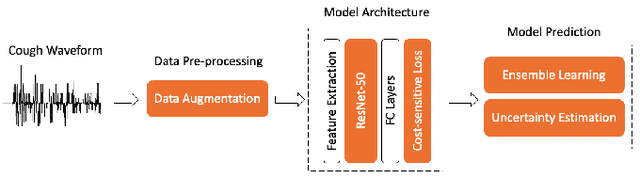
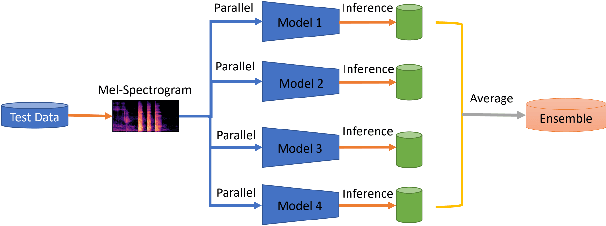
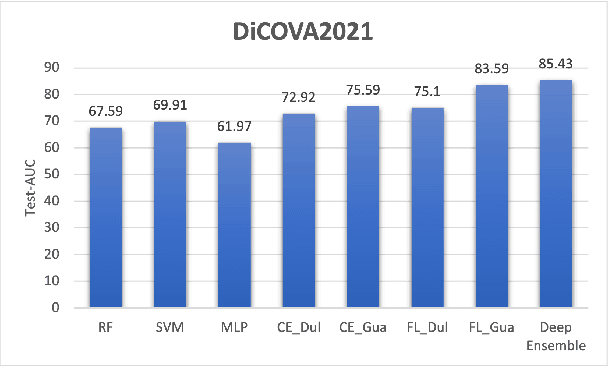
We suggested a unified system with core components of data augmentation, ImageNet-pretrained ResNet-50, cost-sensitive loss, deep ensemble learning, and uncertainty estimation to quickly and consistently detect COVID-19 using acoustic evidence. To increase the model's capacity to identify a minority class, data augmentation and cost-sensitive loss are incorporated (infected samples). In the COVID-19 detection challenge, ImageNet-pretrained ResNet-50 has been found to be effective. The unified framework also integrates deep ensemble learning and uncertainty estimation to integrate predictions from various base classifiers for generalisation and reliability. We ran a series of tests using the DiCOVA2021 challenge dataset to assess the efficacy of our proposed method, and the results show that our method has an AUC-ROC of 85.43 percent, making it a promising method for COVID-19 detection. The unified framework also demonstrates that audio may be used to quickly diagnose different respiratory disorders.
DiCOVA-Net: Diagnosing COVID-19 using Acoustics based on Deep Residual Network for the DiCOVA Challenge 2021
Jul 11, 2021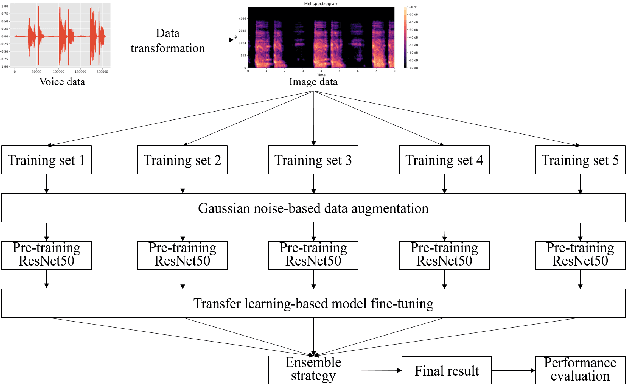
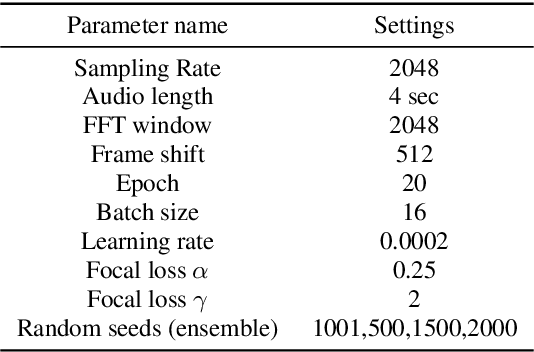


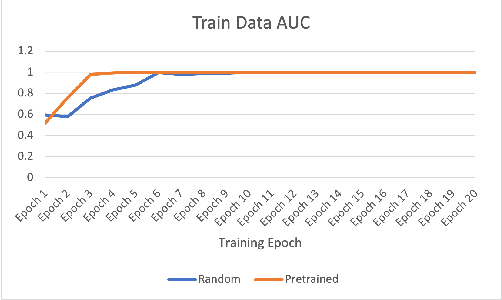
In this paper, we propose a deep residual network-based method, namely the DiCOVA-Net, to identify COVID-19 infected patients based on the acoustic recording of their coughs. Since there are far more healthy people than infected patients, this classification problem faces the challenge of imbalanced data. To improve the model's ability to recognize minority class (the infected patients), we introduce data augmentation and cost-sensitive methods into our model. Besides, considering the particularity of this task, we deploy some fine-tuning techniques to adjust the pre-training ResNet50. Furthermore, to improve the model's generalizability, we use ensemble learning to integrate prediction results from multiple base classifiers generated using different random seeds. To evaluate the proposed DiCOVA-Net's performance, we conducted experiments with the DiCOVA challenge dataset. The results show that our method has achieved 85.43\% in AUC, among the top of all competing teams.
An Auto-ML Framework Based on GBDT for Lifelong Learning
Aug 29, 2019


Automatic Machine Learning (Auto-ML) has attracted more and more attention in recent years, our work is to solve the problem of data drift, which means that the distribution of data will gradually change with the acquisition process, resulting in a worse performance of the auto-ML model. We construct our model based on GBDT, Incremental learning and full learning are used to handle with drift problem. Experiments show that our method performs well on the five data sets. Which shows that our method can effectively solve the problem of data drift and has robust performance.