 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation retrieval for label noise document ranking by bag sampling and group-wise loss
Mar 12, 2022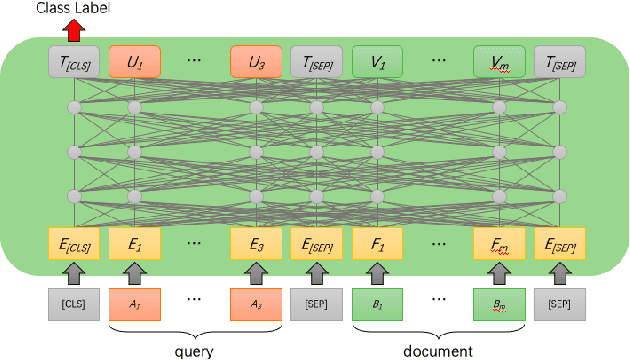
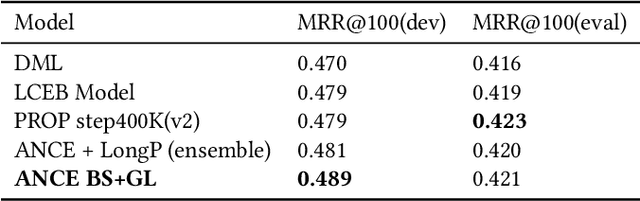
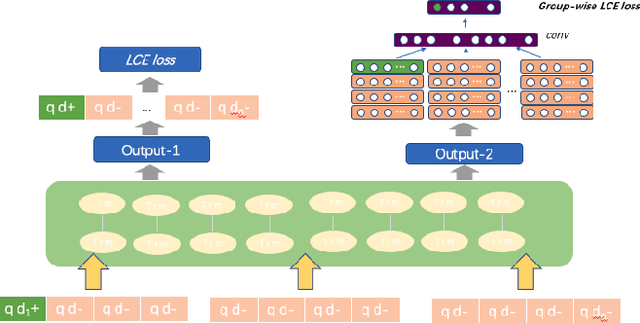
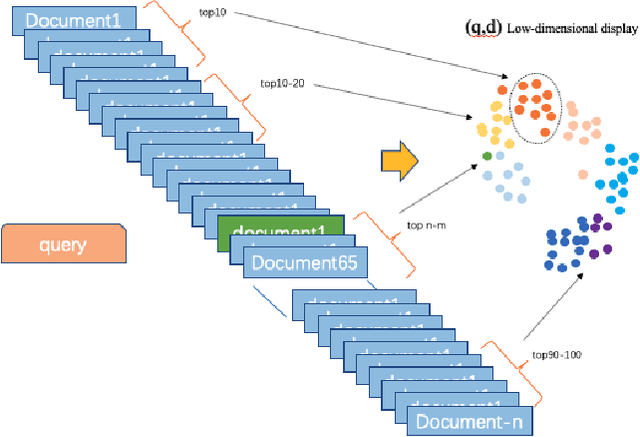
Long Document retrieval (DR) has always been a tremendous challenge for reading comprehension and information retrieval. The pre-training model has achieved good results in the retrieval stage and Ranking for long documents in recent years. However, there is still some crucial problem in long document ranking, such as data label noises, long document representations, negative data Unbalanced sampling, etc. To eliminate the noise of labeled data and to be able to sample the long documents in the search reasonably negatively, we propose the bag sampling method and the group-wise Localized Contrastive Estimation(LCE) method. We use the head middle tail passage for the long document to encode the long document, and in the retrieval, stage Use dense retrieval to generate the candidate's data. The retrieval data is divided into multiple bags at the ranking stage, and negative samples are selected in each bag. After sampling, two losses are combined. The first loss is LCE. To fit bag sampling well, after query and document are encoded, the global features of each group are extracted by convolutional layer and max-pooling to improve the model's resistance to the impact of labeling noise, finally, calculate the LCE group-wise loss. Notably, our model shows excellent performance on the MS MARCO Long document ranking leaderboard.