 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbLog4Fairness: A Neurosymbolic Approach to Modeling and Mitigating Bias
Nov 12, 2025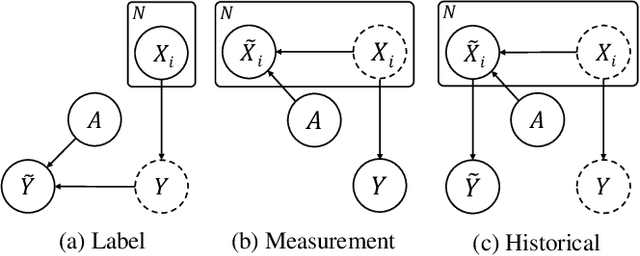

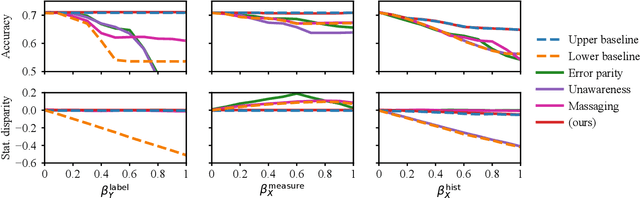

Operationalizing definitions of fairness is difficult in practice, as multiple definitions can be incompatible while each being arguably desirable. Instead, it may be easier to directly describe algorithmic bias through ad-hoc assumptions specific to a particular real-world task, e.g., based on background information on systemic biases in its context. Such assumptions can, in turn, be used to mitigate this bias during training. Yet, a framework for incorporating such assumptions that is simultaneously principled, flexible, and interpretable is currently lacking. Our approach is to formalize bias assumptions as programs in ProbLog, a probabilistic logic programming language that allows for the description of probabilistic causal relationships through logic. Neurosymbolic extensions of ProbLog then allow for easy integration of these assumptions in a neural network's training process. We propose a set of templates to express different types of bias and show the versatility of our approach on synthetic tabular datasets with known biases. Using estimates of the bias distortions present, we also succeed in mitigating algorithmic bias in real-world tabular and image data. We conclude that ProbLog4Fairness outperforms baselines due to its ability to flexibly model the relevant bias assumptions, where other methods typically uphold a fixed bias type or notion of fairness.
Learning From Positive and Unlabeled Data: A Survey
Nov 12, 2018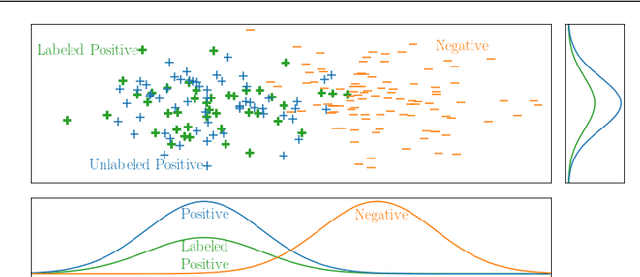
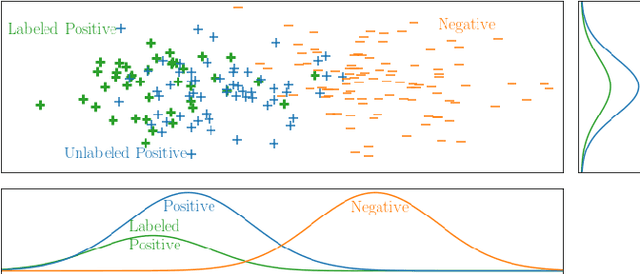

Learning from positive and unlabeled data or PU learning is the setting where a learner only has access to positive examples and unlabeled data. The assumption is that the unlabeled data can contain both positive and negative examples. This setting has attracted increasing interest within the machine learning literature as this type of data naturally arises in applications such as medical diagnosis and knowledge base completion. This article provides a survey of the current state of the art in PU learning. It proposes seven key research questions that commonly arise in this field and provides a broad overview of how the field has tried to address them.
Beyond the Selected Completely At Random Assumption for Learning from Positive and Unlabeled Data
Sep 10, 2018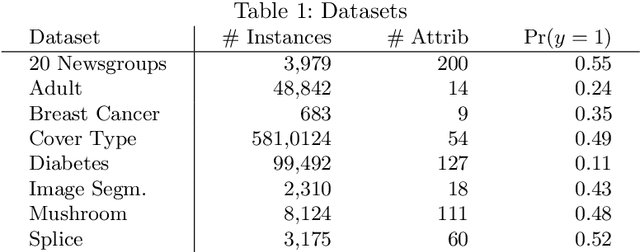

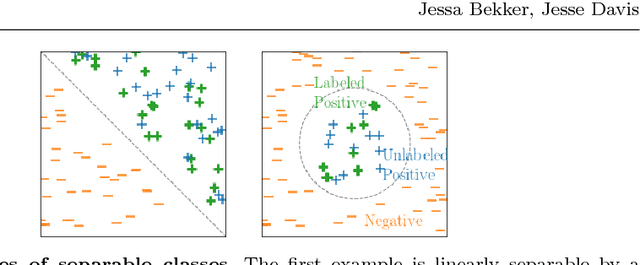
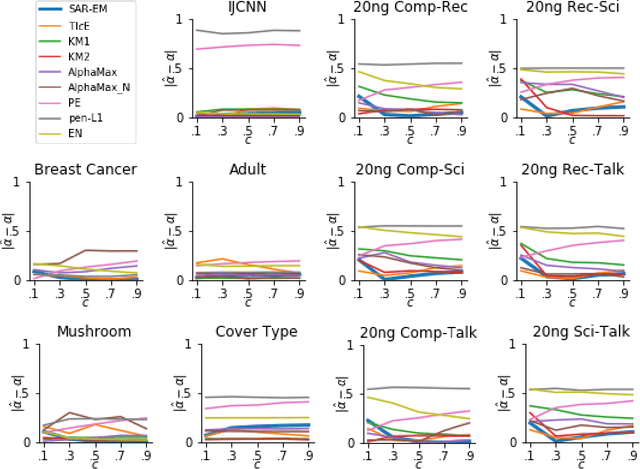
Most positive and unlabeled data is subject to selection biases. The labeled examples can, for example, be selected from the positive set because they are easier to obtain or more obviously positive. This paper investigates how learning can be enabled in this setting. We propose and theoretically analyze an empirical-risk-based method for incorporating the labeling mechanism. Additionally, we investigate under which assumptions learning is possible when the labeling mechanism is not fully understood and propose a practical method to enable this. Our empirical analysis supports the theoretical results and shows that taking into account the possibility of a selection bias, even when the labeling mechanism is unknown, improves the trained classifiers.
Learning from Positive and Unlabeled Data under the Selected At Random Assumption
Aug 27, 2018

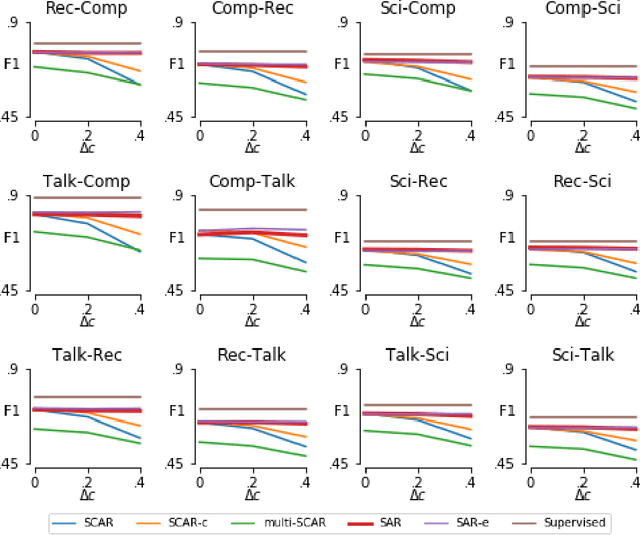
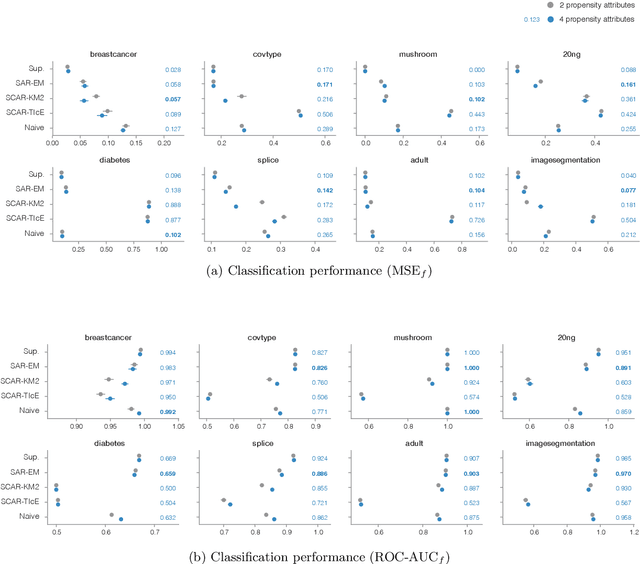
For many interesting tasks, such as medical diagnosis and web page classification, a learner only has access to some positively labeled examples and many unlabeled examples. Learning from this type of data requires making assumptions about the true distribution of the classes and/or the mechanism that was used to select the positive examples to be labeled. The commonly made assumptions, separability of the classes and positive examples being selected completely at random, are very strong. This paper proposes a weaker assumption that assumes the positive examples to be selected at random, conditioned on some of the attributes. To learn under this assumption, an EM method is proposed. Experiments show that our method is not only very capable of learning under this assumption, but it also outperforms the state of the art for learning under the selected completely at random assumption.
Measuring Adverse Drug Effects on Multimorbity using Tractable Bayesian Networks
Dec 09, 2016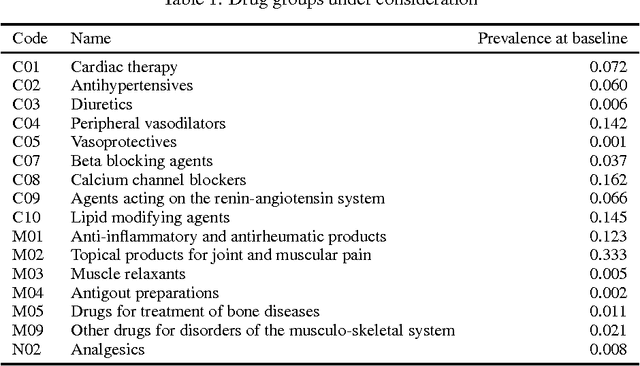
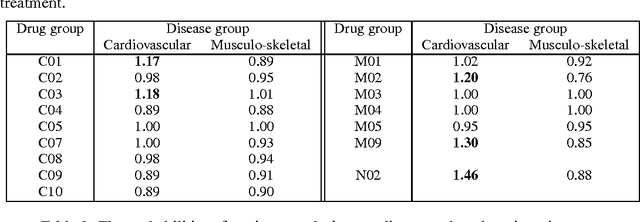

Managing patients with multimorbidity often results in polypharmacy: the prescription of multiple drugs. However, the long-term effects of specific combinations of drugs and diseases are typically unknown. In particular, drugs prescribed for one condition may result in adverse effects for the other. To investigate which types of drugs may affect the further progression of multimorbidity, we query models of diseases and prescriptions that are learned from primary care data. State-of-the-art tractable Bayesian network representations, on which such complex queries can be computed efficiently, are employed for these large medical networks. Our results confirm that prescriptions may lead to unintended negative consequences in further development of multimorbidity in cardiovascular diseases. Moreover, a drug treatment for one disease group may affect diseases of another group.