 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Positive and Unlabeled Data under the Selected At Random Assumption
Paper and Code
Aug 27, 2018
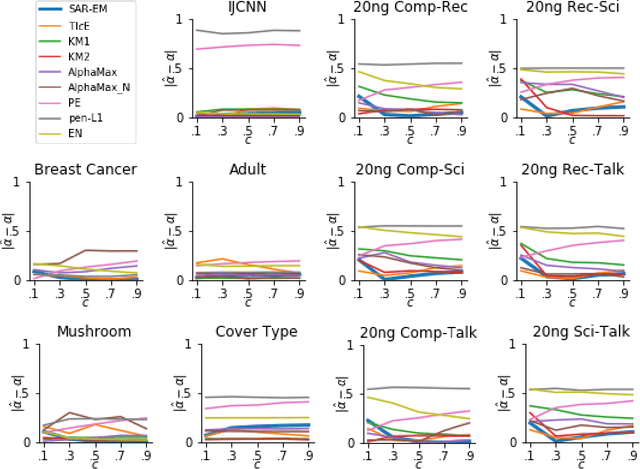

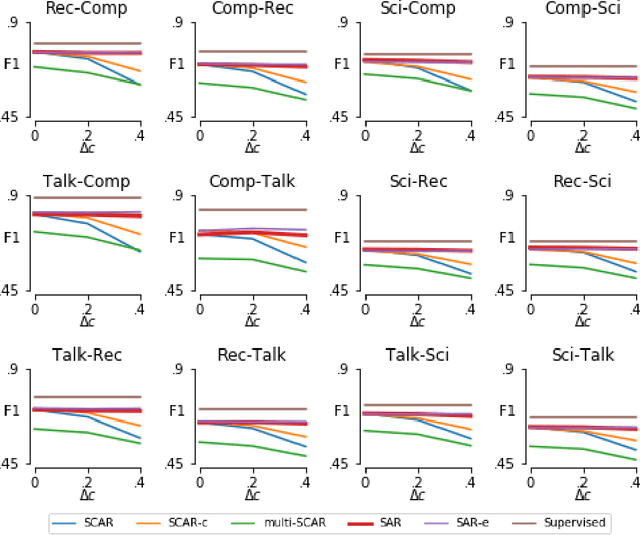
For many interesting tasks, such as medical diagnosis and web page classification, a learner only has access to some positively labeled examples and many unlabeled examples. Learning from this type of data requires making assumptions about the true distribution of the classes and/or the mechanism that was used to select the positive examples to be labeled. The commonly made assumptions, separability of the classes and positive examples being selected completely at random, are very strong. This paper proposes a weaker assumption that assumes the positive examples to be selected at random, conditioned on some of the attributes. To learn under this assumption, an EM method is proposed. Experiments show that our method is not only very capable of learning under this assumption, but it also outperforms the state of the art for learning under the selected completely at random assumption.