 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrastive Self-supervised Learning for Utterance-Level Information Extraction from Speech
Aug 10, 2022

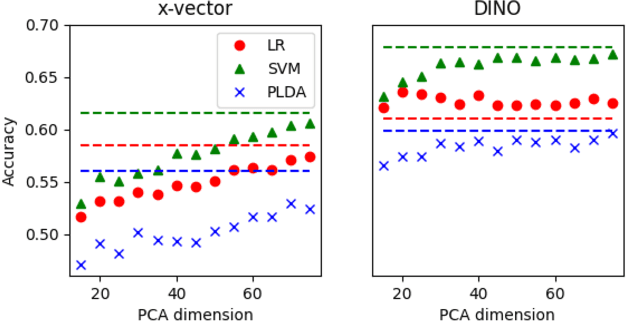

In recent studies, self-supervised pre-trained models tend to outperform supervised pre-trained models in transfer learning. In particular, self-supervised learning (SSL) of utterance-level speech representation can be used in speech applications that require discriminative representation of consistent attributes within an utterance: speaker, language, emotion, and age. Existing frame-level self-supervised speech representation, e.g., wav2vec, can be used as utterance-level representation with pooling, but the models are usually large. There are also SSL techniques to learn utterance-level representation. One of the most successful is a contrastive method, which requires negative sampling: selecting alternative samples to contrast with the current sample (anchor). However, this does not ensure that all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised method to learn utterance-level embeddings. We adapted DIstillation with NO labels (DINO) from computer vision to speech. Unlike contrastive methods, DINO does not require negative sampling. We compared DINO to x-vector trained in a supervised manner. When transferred to down-stream tasks (speaker verification, speech emotion recognition (SER), and Alzheimer's disease detection), DINO outperformed x-vector. We studied the influence of several aspects during transfer learning such as dividing the fine-tuning process into steps, chunk lengths, or augmentation. During fine-tuning, tuning the last affine layers first and then the whole network surpassed fine-tuning all at once. Using shorter chunk lengths, although they generate more diverse inputs, did not necessarily improve performance, implying speech segments at least with a specific length are required for better performance per application. Augmentation was helpful in SER.