 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDGCCA: Supervised Deep Generalized Canonical Correlation Analysis for Multi-omics Integration
Apr 17, 2022
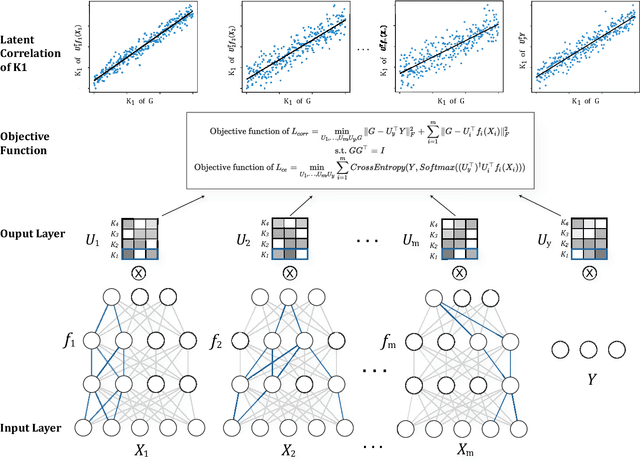
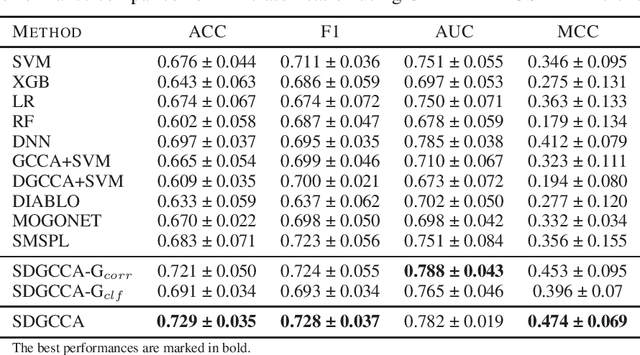

Integration of multi-omics data provides opportunities for revealing biological mechanisms related to certain phenotypes. We propose a novel method of multi-omics integration called supervised deep generalized canonical correlation analysis (SDGCCA) for modeling correlation structures between nonlinear multi-omics manifolds, aiming for improving classification of phenotypes and revealing biomarkers related to phenotypes. SDGCCA addresses the limitations of other canonical correlation analysis (CCA)-based models (e.g., deep CCA, deep generalized CCA) by considering complex/nonlinear cross-data correlations and discriminating phenotype groups. Although there are a few methods for nonlinear CCA projections for discriminant purposes of phenotypes, they only consider two views. On the other hand, SDGCCA is the nonlinear multiview CCA projection method for discrimination. When we applied SDGCCA to prediction of patients of Alzheimer's disease (AD) and discrimination of early- and late-stage cancers, it outperformed other CCA-based methods and other supervised methods. In addition, we demonstrate that SDGCCA can be used for feature selection to identify important multi-omics biomarkers. In the application on AD data, SDGCCA identified clusters of genes in multi-omics data, which are well known to be associated with AD.