 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Neural Sorting Networks with Error-Free Differentiable Swap Functions
Oct 11, 2023



Sorting is a fundamental operation of all computer systems, having been a long-standing significant research topic. Beyond the problem formulation of traditional sorting algorithms, we consider sorting problems for more abstract yet expressive inputs, e.g., multi-digit images and image fragments, through a neural sorting network. To learn a mapping from a high-dimensional input to an ordinal variable, the differentiability of sorting networks needs to be guaranteed. In this paper we define a softening error by a differentiable swap function, and develop an error-free swap function that holds non-decreasing and differentiability conditions. Furthermore, a permutation-equivariant Transformer network with multi-head attention is adopted to capture dependency between given inputs and also leverage its model capacity with self-attention. Experiments on diverse sorting benchmarks show that our methods perform better than or comparable to baseline methods.
Semi-supervised Domain Adaptation via Sample-to-Sample Self-Distillation
Nov 29, 2021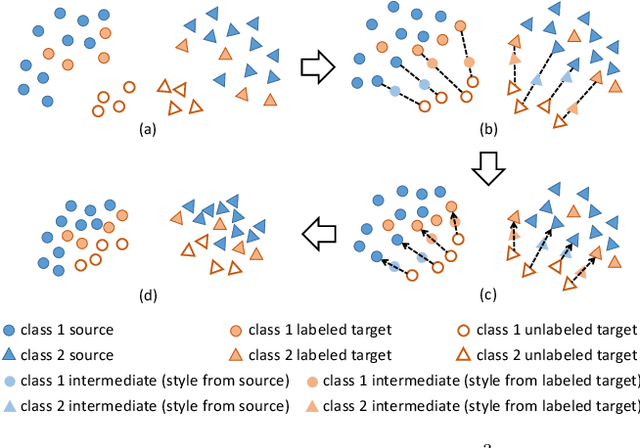

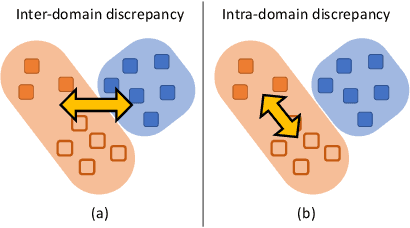
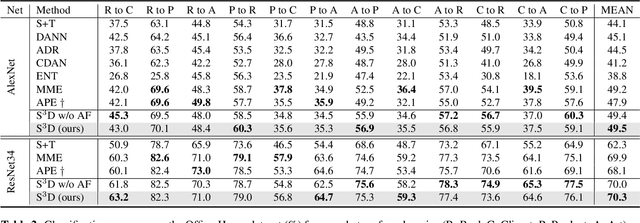
Semi-supervised domain adaptation (SSDA) is to adapt a learner to a new domain with only a small set of labeled samples when a large labeled dataset is given on a source domain. In this paper, we propose a pair-based SSDA method that adapts a model to the target domain using self-distillation with sample pairs. Each sample pair is composed of a teacher sample from a labeled dataset (i.e., source or labeled target) and its student sample from an unlabeled dataset (i.e., unlabeled target). Our method generates an assistant feature by transferring an intermediate style between the teacher and the student, and then train the model by minimizing the output discrepancy between the student and the assistant. During training, the assistants gradually bridge the discrepancy between the two domains, thus allowing the student to easily learn from the teacher. Experimental evaluation on standard benchmarks shows that our method effectively minimizes both the inter-domain and intra-domain discrepancies, thus achieving significant improvements over recent methods.