 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Fusion Model Leveraging MLP Mixer and Handcrafted Features-based Deep Learning Networks for Facial Palsy Detection
Mar 13, 2025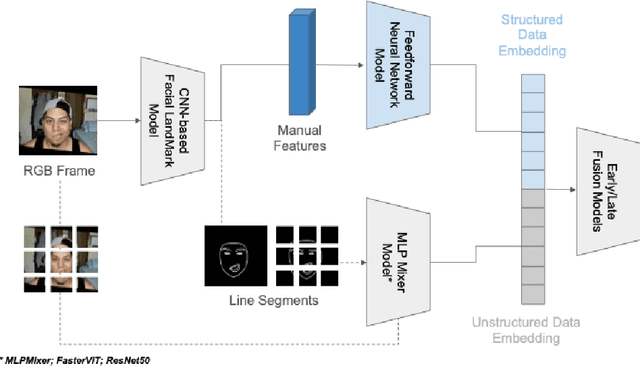


Algorithmic detection of facial palsy offers the potential to improve current practices, which usually involve labor-intensive and subjective assessments by clinicians. In this paper, we present a multimodal fusion-based deep learning model that utilizes an MLP mixer-based model to process unstructured data (i.e. RGB images or images with facial line segments) and a feed-forward neural network to process structured data (i.e. facial landmark coordinates, features of facial expressions, or handcrafted features) for detecting facial palsy. We then contribute to a study to analyze the effect of different data modalities and the benefits of a multimodal fusion-based approach using videos of 20 facial palsy patients and 20 healthy subjects. Our multimodal fusion model achieved 96.00 F1, which is significantly higher than the feed-forward neural network trained on handcrafted features alone (82.80 F1) and an MLP mixer-based model trained on raw RGB images (89.00 F1).
Exploring a Multimodal Fusion-based Deep Learning Network for Detecting Facial Palsy
May 26, 2024Algorithmic detection of facial palsy offers the potential to improve current practices, which usually involve labor-intensive and subjective assessment by clinicians. In this paper, we present a multimodal fusion-based deep learning model that utilizes unstructured data (i.e. an image frame with facial line segments) and structured data (i.e. features of facial expressions) to detect facial palsy. We then contribute to a study to analyze the effect of different data modalities and the benefits of a multimodal fusion-based approach using videos of 21 facial palsy patients. Our experimental results show that among various data modalities (i.e. unstructured data - RGB images and images of facial line segments and structured data - coordinates of facial landmarks and features of facial expressions), the feed-forward neural network using features of facial expression achieved the highest precision of 76.22 while the ResNet-based model using images of facial line segments achieved the highest recall of 83.47. When we leveraged both images of facial line segments and features of facial expressions, our multimodal fusion-based deep learning model slightly improved the precision score to 77.05 at the expense of a decrease in the recall score.