 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Fusion Model Leveraging MLP Mixer and Handcrafted Features-based Deep Learning Networks for Facial Palsy Detection
Paper and Code
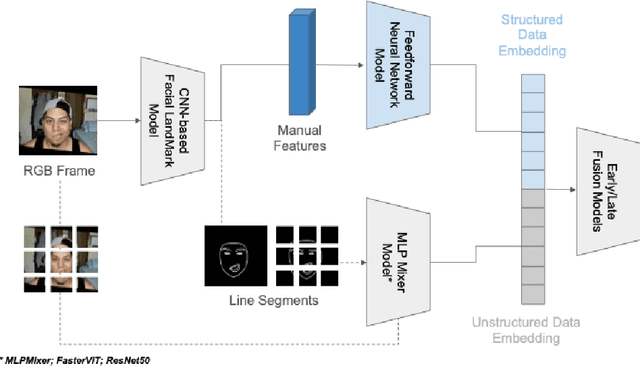


Algorithmic detection of facial palsy offers the potential to improve current practices, which usually involve labor-intensive and subjective assessments by clinicians. In this paper, we present a multimodal fusion-based deep learning model that utilizes an MLP mixer-based model to process unstructured data (i.e. RGB images or images with facial line segments) and a feed-forward neural network to process structured data (i.e. facial landmark coordinates, features of facial expressions, or handcrafted features) for detecting facial palsy. We then contribute to a study to analyze the effect of different data modalities and the benefits of a multimodal fusion-based approach using videos of 20 facial palsy patients and 20 healthy subjects. Our multimodal fusion model achieved 96.00 F1, which is significantly higher than the feed-forward neural network trained on handcrafted features alone (82.80 F1) and an MLP mixer-based model trained on raw RGB images (89.00 F1).