 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking e-cigarette warning label compliance on Instagram with deep learning
Feb 08, 2021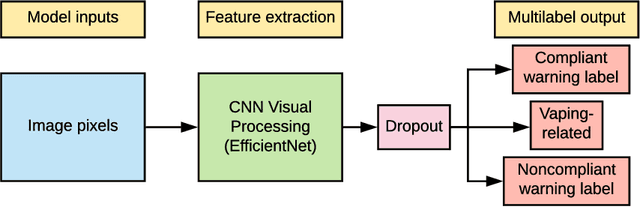

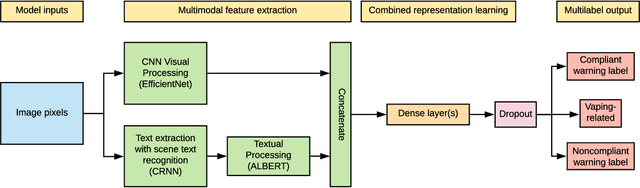
The U.S. Food & Drug Administration (FDA) requires that e-cigarette advertisements include a prominent warning label that reminds consumers that nicotine is addictive. However, the high volume of vaping-related posts on social media makes compliance auditing expensive and time-consuming, suggesting that an automated, scalable method is needed. We sought to develop and evaluate a deep learning system designed to automatically determine if an Instagram post promotes vaping, and if so, if an FDA-compliant warning label was included or if a non-compliant warning label was visible in the image. We compiled and labeled a dataset of 4,363 Instagram images, of which 44% were vaping-related, 3% contained FDA-compliant warning labels, and 4% contained non-compliant labels. Using a 20% test set for evaluation, we tested multiple neural network variations: image processing backbone model (Inceptionv3, ResNet50, EfficientNet), data augmentation, progressive layer unfreezing, output bias initialization designed for class imbalance, and multitask learning. Our final model achieved an area under the curve (AUC) and [accuracy] of 0.97 [92%] on vaping classification, 0.99 [99%] on FDA-compliant warning labels, and 0.94 [97%] on non-compliant warning labels. We conclude that deep learning models can effectively identify vaping posts on Instagram and track compliance with FDA warning label requirements.
Automated identification of hookahs (waterpipes) on Instagram: an application in feature extraction using Convolutional Neural Network and Support Vector Machine classification
Oct 21, 2018
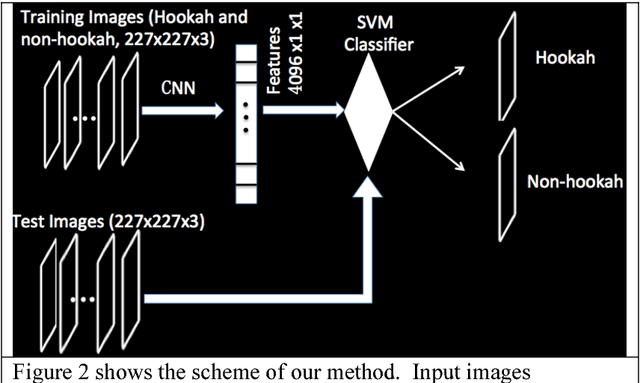


Background: Instagram, with millions of posts per day, can be used to inform public health surveillance targets and policies. However, current research relying on image-based data often relies on hand coding of images which is time consuming and costly, ultimately limiting the scope of the study. Current best practices in automated image classification (e.g., support vector machine (SVM), Backpropagation (BP) neural network, and artificial neural network) are limited in their capacity to accurately distinguish between objects within images. Objective: This study demonstrates how convolutional neural network (CNN) can be used to extract unique features within an image and how SVM can then be used to classify the image. Methods: Images of waterpipes or hookah (an emerging tobacco product possessing similar harms to that of cigarettes) were collected from Instagram and used in analyses (n=840). CNN was used to extract unique features from images identified to contain waterpipes. A SVM classifier was built to distinguish between images with and without waterpipes. Methods for image classification were then compared to show how a CNN + SVM classifier could improve accuracy. Results: As the number of the validated training images increased, the total number of extracted features increased. Additionally, as the number of features learned by the SVM classifier increased, the average level of accuracy increased. Overall, 99.5% of the 420 images classified were correctly identified as either hookah or non-hookah images. This level of accuracy was an improvement over earlier methods that used SVM, CNN or Bag of Features (BOF) alone. Conclusions: CNN extracts more features of the images allowing a SVM classifier to be better informed, resulting in higher accuracy compared with methods that extract fewer features. Future research can use this method to grow the scope of image-based studies.