 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGossipGraD: Scalable Deep Learning using Gossip Communication based Asynchronous Gradient Descent
Mar 15, 2018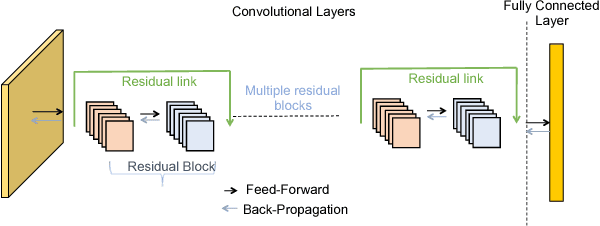
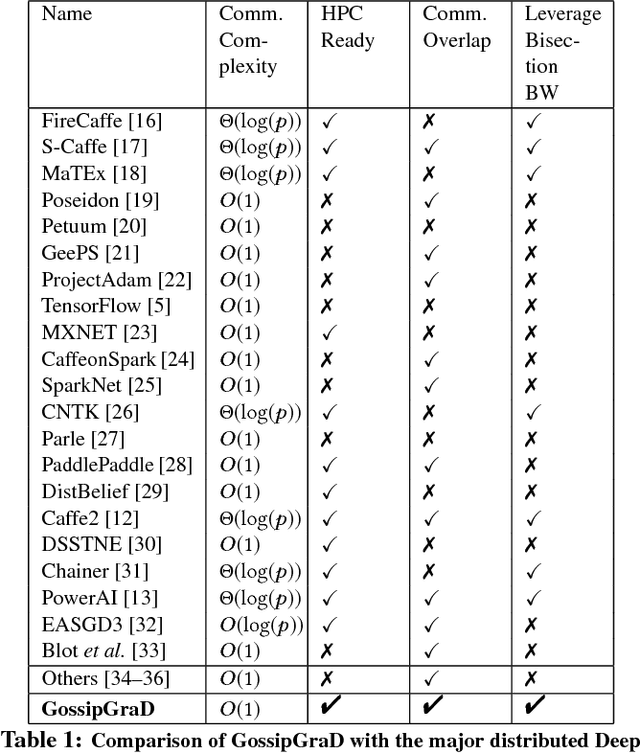
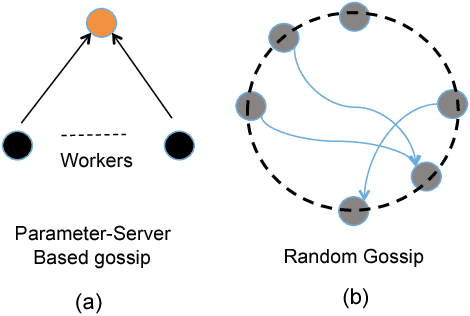

In this paper, we present GossipGraD - a gossip communication protocol based Stochastic Gradient Descent (SGD) algorithm for scaling Deep Learning (DL) algorithms on large-scale systems. The salient features of GossipGraD are: 1) reduction in overall communication complexity from {\Theta}(log(p)) for p compute nodes in well-studied SGD to O(1), 2) model diffusion such that compute nodes exchange their updates (gradients) indirectly after every log(p) steps, 3) rotation of communication partners for facilitating direct diffusion of gradients, 4) asynchronous distributed shuffle of samples during the feedforward phase in SGD to prevent over-fitting, 5) asynchronous communication of gradients for further reducing the communication cost of SGD and GossipGraD. We implement GossipGraD for GPU and CPU clusters and use NVIDIA GPUs (Pascal P100) connected with InfiniBand, and Intel Knights Landing (KNL) connected with Aries network. We evaluate GossipGraD using well-studied dataset ImageNet-1K (~250GB), and widely studied neural network topologies such as GoogLeNet and ResNet50 (current winner of ImageNet Large Scale Visualization Research Challenge (ILSVRC)). Our performance evaluation using both KNL and Pascal GPUs indicates that GossipGraD can achieve perfect efficiency for these datasets and their associated neural network topologies. Specifically, for ResNet50, GossipGraD is able to achieve ~100% compute efficiency using 128 NVIDIA Pascal P100 GPUs - while matching the top-1 classification accuracy published in literature.
Adaptive Neuron Apoptosis for Accelerating Deep Learning on Large Scale Systems
Oct 03, 2016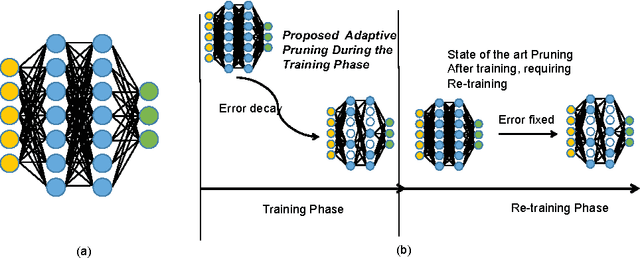
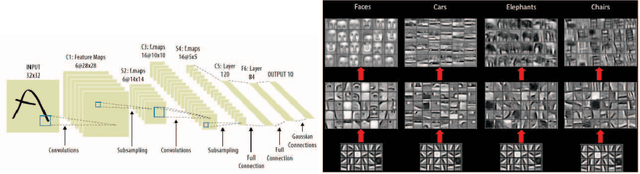
We present novel techniques to accelerate the convergence of Deep Learning algorithms by conducting low overhead removal of redundant neurons -- apoptosis of neurons -- which do not contribute to model learning, during the training phase itself. We provide in-depth theoretical underpinnings of our heuristics (bounding accuracy loss and handling apoptosis of several neuron types), and present the methods to conduct adaptive neuron apoptosis. Specifically, we are able to improve the training time for several datasets by 2-3x, while reducing the number of parameters by up to 30x (4-5x on average) on datasets such as ImageNet classification. For the Higgs Boson dataset, our implementation improves the accuracy (measured by Area Under Curve (AUC)) for classification from 0.88/1 to 0.94/1, while reducing the number of parameters by 3x in comparison to existing literature. The proposed methods achieve a 2.44x speedup in comparison to the default (no apoptosis) algorithm.