 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Volume Rate 3D Ultrasound Reconstruction with Diffusion Models
May 28, 2025Three-dimensional ultrasound enables real-time volumetric visualization of anatomical structures. Unlike traditional 2D ultrasound, 3D imaging reduces the reliance on precise probe orientation, potentially making ultrasound more accessible to clinicians with varying levels of experience and improving automated measurements and post-exam analysis. However, achieving both high volume rates and high image quality remains a significant challenge. While 3D diverging waves can provide high volume rates, they suffer from limited tissue harmonic generation and increased multipath effects, which degrade image quality. One compromise is to retain the focusing in elevation while leveraging unfocused diverging waves in the lateral direction to reduce the number of transmissions per elevation plane. Reaching the volume rates achieved by full 3D diverging waves, however, requires dramatically undersampling the number of elevation planes. Subsequently, to render the full volume, simple interpolation techniques are applied. This paper introduces a novel approach to 3D ultrasound reconstruction from a reduced set of elevation planes by employing diffusion models (DMs) to achieve increased spatial and temporal resolution. We compare both traditional and supervised deep learning-based interpolation methods on a 3D cardiac ultrasound dataset. Our results show that DM-based reconstruction consistently outperforms the baselines in image quality and downstream task performance. Additionally, we accelerate inference by leveraging the temporal consistency inherent to ultrasound sequences. Finally, we explore the robustness of the proposed method by exploiting the probabilistic nature of diffusion posterior sampling to quantify reconstruction uncertainty and demonstrate improved recall on out-of-distribution data with synthetic anomalies under strong subsampling.
Sequential Posterior Sampling with Diffusion Models
Sep 09, 2024
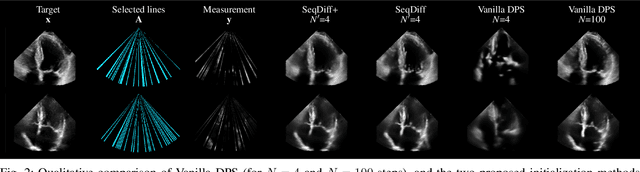
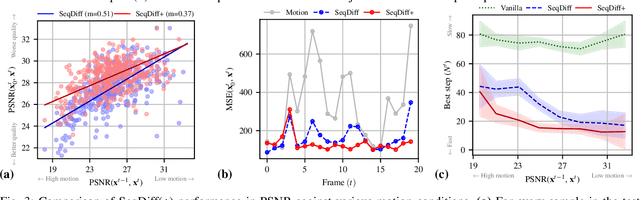
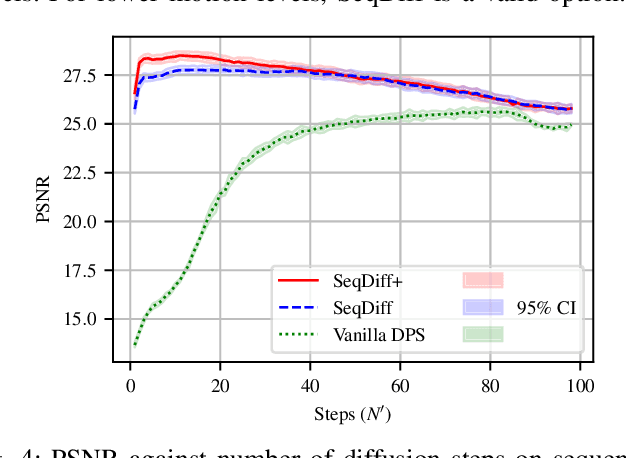
Diffusion models have quickly risen in popularity for their ability to model complex distributions and perform effective posterior sampling. Unfortunately, the iterative nature of these generative models makes them computationally expensive and unsuitable for real-time sequential inverse problems such as ultrasound imaging. Considering the strong temporal structure across sequences of frames, we propose a novel approach that models the transition dynamics to improve the efficiency of sequential diffusion posterior sampling in conditional image synthesis. Through modeling sequence data using a video vision transformer (ViViT) transition model based on previous diffusion outputs, we can initialize the reverse diffusion trajectory at a lower noise scale, greatly reducing the number of iterations required for convergence. We demonstrate the effectiveness of our approach on a real-world dataset of high frame rate cardiac ultrasound images and show that it achieves the same performance as a full diffusion trajectory while accelerating inference 25$\times$, enabling real-time posterior sampling. Furthermore, we show that the addition of a transition model improves the PSNR up to 8\% in cases with severe motion. Our method opens up new possibilities for real-time applications of diffusion models in imaging and other domains requiring real-time inference.
Dehazing Ultrasound using Diffusion Models
Jul 20, 2023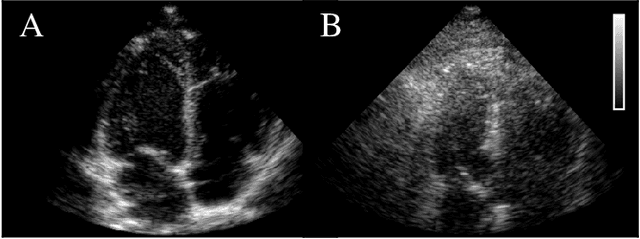
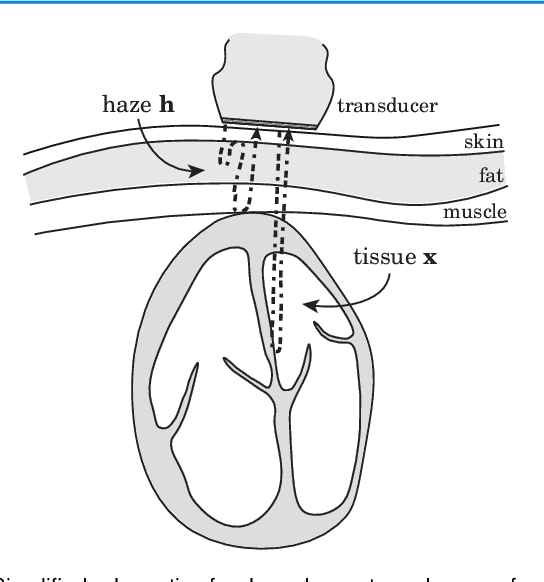
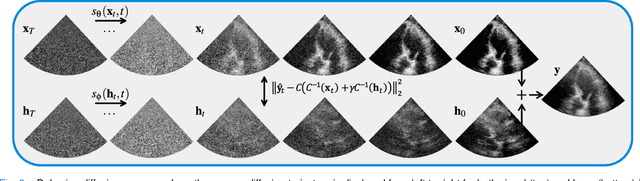
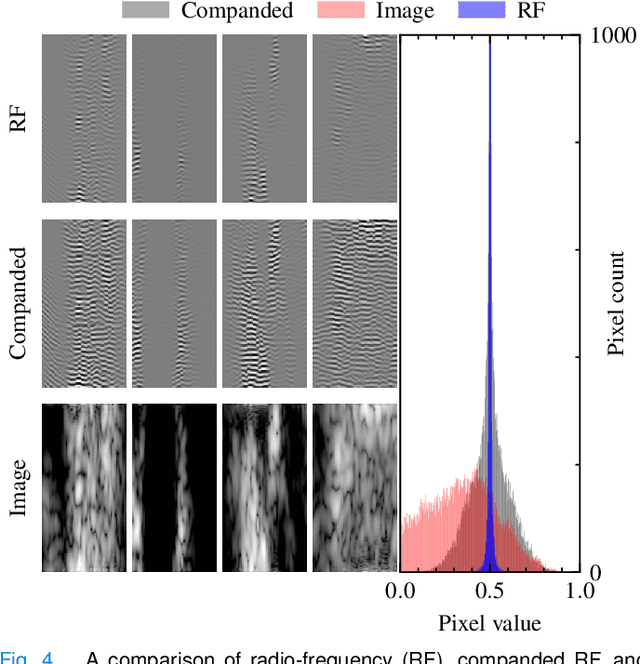
Echocardiography has been a prominent tool for the diagnosis of cardiac disease. However, these diagnoses can be heavily impeded by poor image quality. Acoustic clutter emerges due to multipath reflections imposed by layers of skin, subcutaneous fat, and intercostal muscle between the transducer and heart. As a result, haze and other noise artifacts pose a real challenge to cardiac ultrasound imaging. In many cases, especially with difficult-to-image patients such as patients with obesity, a diagnosis from B-Mode ultrasound imaging is effectively rendered unusable, forcing sonographers to resort to contrast-enhanced ultrasound examinations or refer patients to other imaging modalities. Tissue harmonic imaging has been a popular approach to combat haze, but in severe cases is still heavily impacted by haze. Alternatively, denoising algorithms are typically unable to remove highly structured and correlated noise, such as haze. It remains a challenge to accurately describe the statistical properties of structured haze, and develop an inference method to subsequently remove it. Diffusion models have emerged as powerful generative models and have shown their effectiveness in a variety of inverse problems. In this work, we present a joint posterior sampling framework that combines two separate diffusion models to model the distribution of both clean ultrasound and haze in an unsupervised manner. Furthermore, we demonstrate techniques for effectively training diffusion models on radio-frequency ultrasound data and highlight the advantages over image data. Experiments on both \emph{in-vitro} and \emph{in-vivo} cardiac datasets show that the proposed dehazing method effectively removes haze while preserving signals from weakly reflected tissue.