 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark of structured machine learning methods for microbial identification from mass-spectrometry data
Jun 24, 2015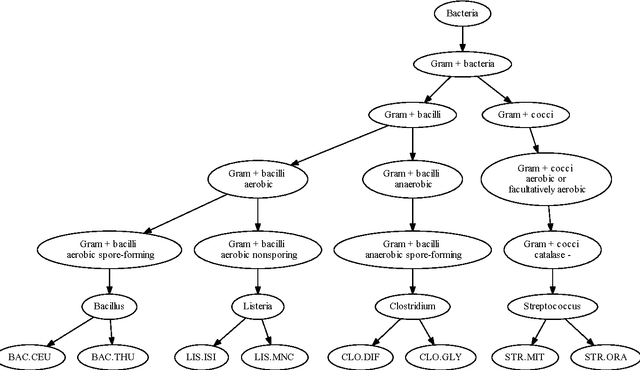

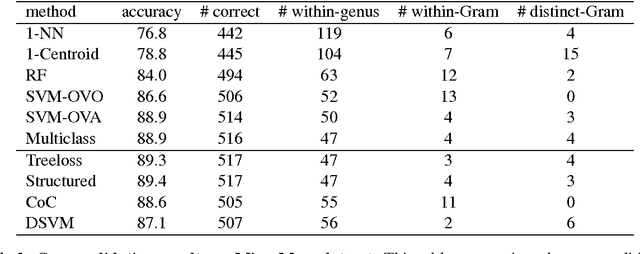

Microbial identification is a central issue in microbiology, in particular in the fields of infectious diseases diagnosis and industrial quality control. The concept of species is tightly linked to the concept of biological and clinical classification where the proximity between species is generally measured in terms of evolutionary distances and/or clinical phenotypes. Surprisingly, the information provided by this well-known hierarchical structure is rarely used by machine learning-based automatic microbial identification systems. Structured machine learning methods were recently proposed for taking into account the structure embedded in a hierarchy and using it as additional a priori information, and could therefore allow to improve microbial identification systems. We test and compare several state-of-the-art machine learning methods for microbial identification on a new Matrix-Assisted Laser Desorption/Ionization Time-of-Flight mass spectrometry (MALDI-TOF MS) dataset. We include in the benchmark standard and structured methods, that leverage the knowledge of the underlying hierarchical structure in the learning process. Our results show that although some methods perform better than others, structured methods do not consistently perform better than their "flat" counterparts. We postulate that this is partly due to the fact that standard methods already reach a high level of accuracy in this context, and that they mainly confuse species close to each other in the tree, a case where using the known hierarchy is not helpful.
Large-scale Machine Learning for Metagenomics Sequence Classification
May 26, 2015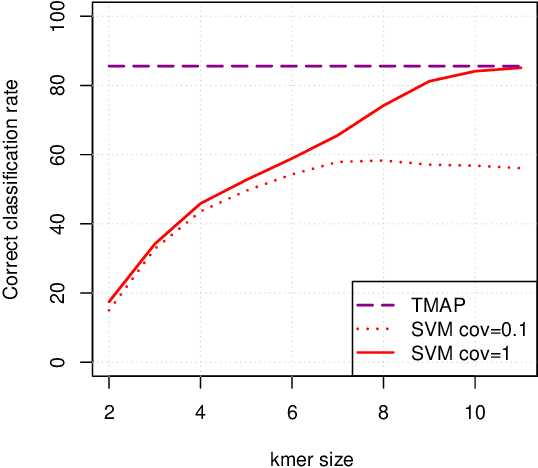
Metagenomics characterizes the taxonomic diversity of microbial communities by sequencing DNA directly from an environmental sample. One of the main challenges in metagenomics data analysis is the binning step, where each sequenced read is assigned to a taxonomic clade. Due to the large volume of metagenomics datasets, binning methods need fast and accurate algorithms that can operate with reasonable computing requirements. While standard alignment-based methods provide state-of-the-art performance, compositional approaches that assign a taxonomic class to a DNA read based on the k-mers it contains have the potential to provide faster solutions. In this work, we investigate the potential of modern, large-scale machine learning implementations for taxonomic affectation of next-generation sequencing reads based on their k-mers profile. We show that machine learning-based compositional approaches benefit from increasing the number of fragments sampled from reference genome to tune their parameters, up to a coverage of about 10, and from increasing the k-mer size to about 12. Tuning these models involves training a machine learning model on about 10 8 samples in 10 7 dimensions, which is out of reach of standard soft-wares but can be done efficiently with modern implementations for large-scale machine learning. The resulting models are competitive in terms of accuracy with well-established alignment tools for problems involving a small to moderate number of candidate species, and for reasonable amounts of sequencing errors. We show, however, that compositional approaches are still limited in their ability to deal with problems involving a greater number of species, and more sensitive to sequencing errors. We finally confirm that compositional approach achieve faster prediction times, with a gain of 3 to 15 times with respect to the BWA-MEM short read mapper, depending on the number of candidate species and the level of sequencing noise.