 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Weak Coresets for Non-Decomposable Classification Measures
Dec 15, 2023While coresets have been growing in terms of their application, barring few exceptions, they have mostly been limited to unsupervised settings. We consider supervised classification problems, and non-decomposable evaluation measures in such settings. We show that stratified uniform sampling based coresets have excellent empirical performance that are backed by theoretical guarantees too. We focus on the F1 score and Matthews Correlation Coefficient, two widely used non-decomposable objective functions that are nontrivial to optimize for and show that uniform coresets attain a lower bound for coreset size, and have good empirical performance, comparable with ``smarter'' coreset construction strategies.
Survey on Modeling Intensity Function of Hawkes Process Using Neural Models
Apr 22, 2021
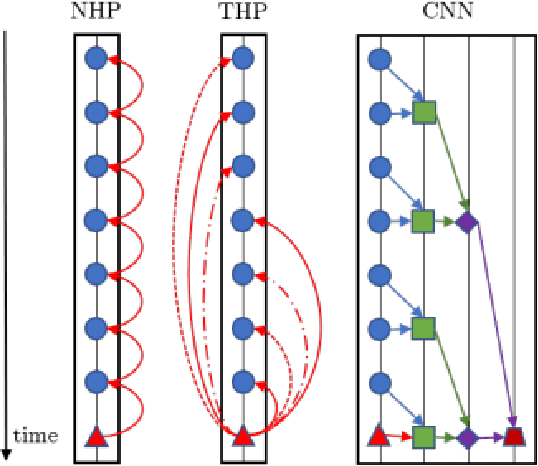
The event sequence of many diverse systems is represented as a sequence of discrete events in a continuous space. Examples of such an event sequence are earthquake aftershock events, financial transactions, e-commerce transactions, social network activity of a user, and the user's web search pattern. Finding such an intricate pattern helps discover which event will occur in the future and when it will occur. A Hawkes process is a mathematical tool used for modeling such time series discrete events. Traditionally, the Hawkes process uses a critical component for modeling data as an intensity function with a parameterized kernel function. The Hawkes process's intensity function involves two components: the background intensity and the effect of events' history. However, such parameterized assumption can not capture future event characteristics using past events data precisely due to bias in modeling kernel function. This paper explores the recent advancement using novel deep learning-based methods to model kernel function to remove such parametrized kernel function. In the end, we will give potential future research directions to improve modeling using the Hawkes process.