 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Collapse as Mismatched Decoding: Information-Theoretic Limits of Multimodal LLMs
Feb 26, 2026Multimodal LLMs can process speech and images, but they cannot hear a speaker's voice or see an object's texture. We show this is not a failure of encoding: speaker identity, emotion, and visual attributes survive through every LLM layer (3--55$\times$ above chance in linear probes), yet removing 64--71% of modality-specific variance improves decoder loss. The decoder has no learned use for these directions; their presence is noise. We formalize this as a mismatched decoder problem: a decoder trained on text can only extract information along text-aligned directions. Accessible information is bounded by the Generalized Mutual Information (GMI), with degradation scaling with distributional distance and decoder sensitivity. The bound is a property of the decoder's scoring rule, not of any particular architecture; it applies whether non-text inputs arrive through a learned projection, a discrete codebook, or no explicit adapter at all. We validate this across five models spanning speech and vision. A controlled experiment (two Prismatic VLMs differing only in encoder text-alignment) confirms the bottleneck is the decoder's scoring rule, not the encoder or projection. A LoRA intervention demonstrates the fix: training with an emotion objective improves emotion accessibility ($+$7.5%) without affecting other attributes, confirming that the training objective determines what becomes accessible.
The Cascade Equivalence Hypothesis: When Do Speech LLMs Behave Like ASR$\rightarrow$LLM Pipelines?
Feb 19, 2026Current speech LLMs largely perform implicit ASR: on tasks solvable from a transcript, they are behaviorally and mechanistically equivalent to simple Whisper$\to$LLM cascades. We show this through matched-backbone testing across four speech LLMs and six tasks, controlling for the LLM backbone for the first time. Ultravox is statistically indistinguishable from its matched cascade ($κ{=}0.93$); logit lens reveals literal text emerging in hidden states; LEACE concept erasure confirms text representations are causally necessary in both architectures tested, collapsing accuracy to near-zero. Qwen2-Audio genuinely diverges, revealing cascade equivalence is architecture-dependent, not universal. For most deployed use cases, current speech LLMs are expensive cascades, and under noise, they are worse ones, with clean-condition advantages reversing by up to 7.6% at 0 dB.
Anatomy of Capability Emergence: Scale-Invariant Representation Collapse and Top-Down Reorganization in Neural Networks
Feb 17, 2026Capability emergence during neural network training remains mechanistically opaque. We track five geometric measures across five model scales (405K-85M parameters), 120+ emergence events in eight algorithmic tasks, and three Pythia language models (160M-2.8B). We find: (1) training begins with a universal representation collapse to task-specific floors that are scale-invariant across a 210X parameter range (e.g., modular arithmetic collapses to RANKME ~ 2.0 regardless of model size); (2) collapse propagates top-down through layers (32/32 task X model consistency), contradicting bottom-up feature-building intuition; (3) a geometric hierarchy in which representation geometry leads emergence (75-100% precursor rate for hard tasks), while the local learning coefficient is synchronous (0/24 precursor) and Hessian measures lag. We also delineate prediction limits: geometric measures encode coarse task difficulty but not fine-grained timing (within-class concordance 27%; when task ordering reverses across scales, prediction fails at 26%). On Pythia, global geometric patterns replicate but per-task precursor signals do not -- the precursor relationship requires task-training alignment that naturalistic pre-training does not provide. Our contribution is the geometric anatomy of emergence and its boundary conditions, not a prediction tool.
When Audio-LLMs Don't Listen: A Cross-Linguistic Study of Modality Arbitration
Feb 12, 2026When audio and text conflict, speech-enabled language models follow the text 10 times more often than when arbitrating between two text sources, even when explicitly instructed to trust the audio. Using ALME, a benchmark of 57,602 controlled audio-text conflict stimuli across 8 languages, we find that Gemini 2.0 Flash exhibits 16.6\% text dominance under audio-text conflict versus 1.6\% under text-text conflict with identical reliability cues. This gap is not explained by audio quality: audio-only accuracy (97.2\%) exceeds cascade accuracy (93.9\%), indicating audio embeddings preserve more information than text transcripts. We propose that text dominance reflects an asymmetry not in information content but in arbitration accessibility: how easily the model can reason over competing representations. This framework explains otherwise puzzling findings. Forcing transcription before answering increases text dominance (19\% to 33\%), sacrificing audio's information advantage without improving accessibility. Framing text as ``deliberately corrupted'' reduces text dominance by 80\%. A fine-tuning ablation provides interventional evidence: training only the audio projection layer increases text dominance (+26.5\%), while LoRA on the language model halves it ($-$23.9\%), localizing text dominance to the LLM's reasoning rather than the audio encoder. Experiments across four state-of-the-art audio-LLMs and 8 languages show consistent trends with substantial cross-linguistic and cross-model variation, establishing modality arbitration as a distinct reliability dimension not captured by standard speech benchmarks.
Improving Low-Resource Speech Recognition with Pretrained Speech Models: Continued Pretraining vs. Semi-Supervised Training
Jul 01, 2022
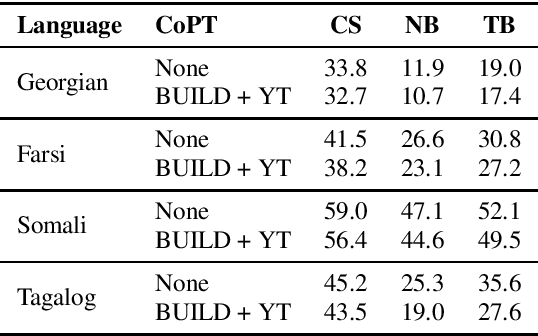
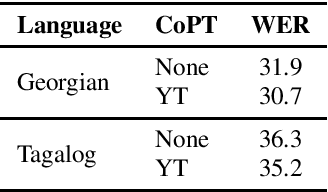
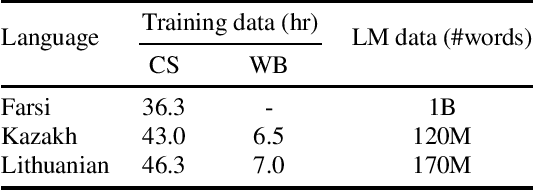
Self-supervised Transformer based models, such as wav2vec 2.0 and HuBERT, have produced significant improvements over existing approaches to automatic speech recognition (ASR). This is evident in the performance of the wav2vec 2.0 based pretrained XLSR-53 model across many languages when fine-tuned with available labeled data. However, the performance from finetuning these models can be dependent on the amount of in-language or similar-to-in-language data included in the pretraining dataset. In this paper we investigate continued pretraining (CoPT) with unlabeled in-language audio data on the XLSR-53 pretrained model in several low-resource languages. CoPT is more computationally efficient than semi-supervised training (SST), the standard approach of utilizing unlabeled data in ASR, since it omits the need for pseudo-labeling of the unlabeled data. We show CoPT results in word error rates (WERs), equal to or slightly better than using SST. In addition, we show that using the CoPT model for pseudo-labeling, and using these labels in SST, results in further improvements in WER.
Improving low-resource ASR performance with untranscribed out-of-domain data
Jun 02, 2021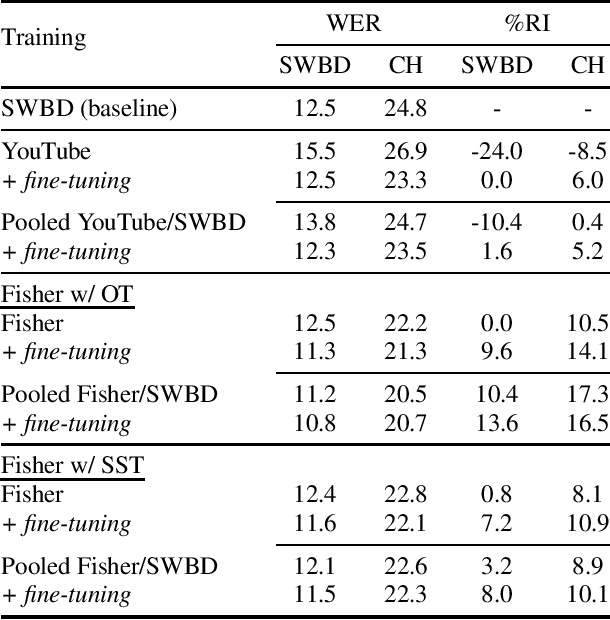
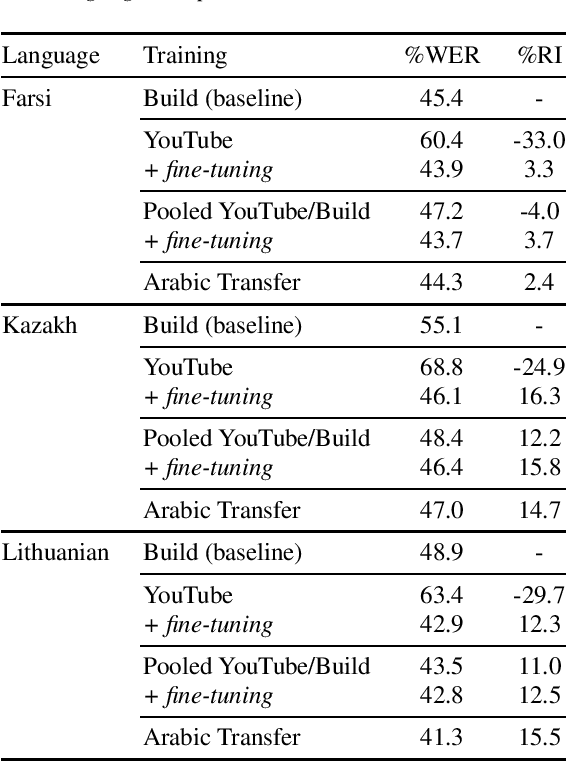
Semi-supervised training (SST) is a common approach to leverage untranscribed/unlabeled speech data to improve automatic speech recognition performance in low-resource languages. However, if the available unlabeled speech is mismatched to the target domain, SST is not as effective, and in many cases performs worse than the original system. In this paper, we address the issue of low-resource ASR when only untranscribed out-of-domain speech data is readily available in the target language. Specifically, we look to improve performance on conversational/telephony speech (target domain) using web resources, in particular YouTube data, which more closely resembles news/topical broadcast data. Leveraging SST, we show that while in some cases simply pooling the out-of-domain data with the training data lowers word error rate (WER), in all cases, we see improvements if we train first with the out-of-domain data and then fine-tune the resulting model with the original training data. Using 2000 hours of speed perturbed YouTube audio in each target language, with semi-supervised transcripts, we show improvements on multiple languages/data sets, of up to 16.3% relative improvement in WER over the baseline systems and up to 7.4% relative improvement in WER over a system that simply pools the out-of-domain data with the training data.
Improving LSTM-CTC based ASR performance in domains with limited training data
May 23, 2018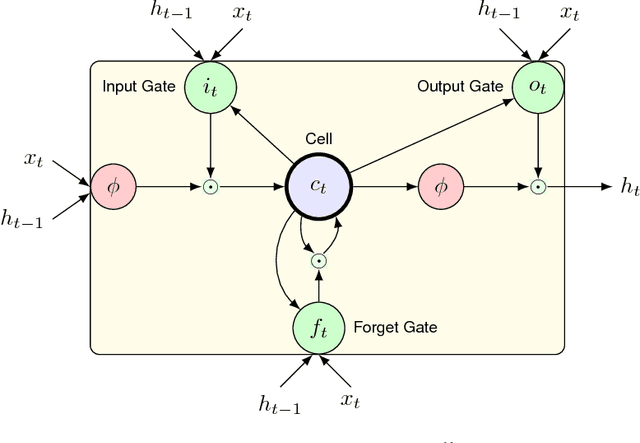


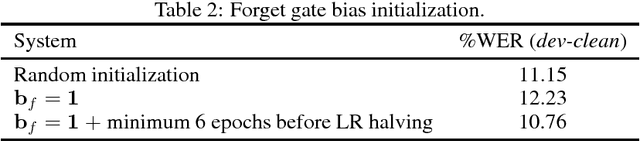
This paper addresses the observed performance gap between automatic speech recognition (ASR) systems based on Long Short Term Memory (LSTM) neural networks trained with the connectionist temporal classification (CTC) loss function and systems based on hybrid Deep Neural Networks (DNNs) trained with the cross entropy (CE) loss function on domains with limited data. We step through a number of experiments that show incremental improvements on a baseline EESEN toolkit based LSTM-CTC ASR system trained on the Librispeech 100hr (train-clean-100) corpus. Our results show that with effective combination of data augmentation and regularization, a LSTM-CTC based system can exceed the performance of a strong Kaldi based baseline trained on the same data.