 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving low-resource ASR performance with untranscribed out-of-domain data
Paper and Code
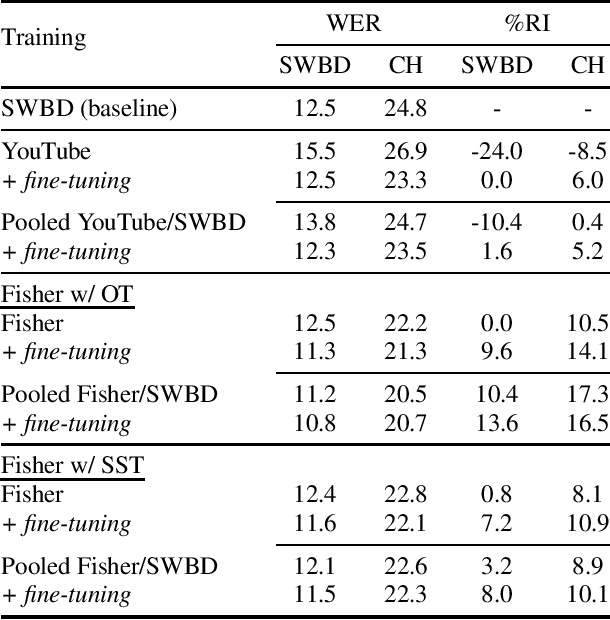
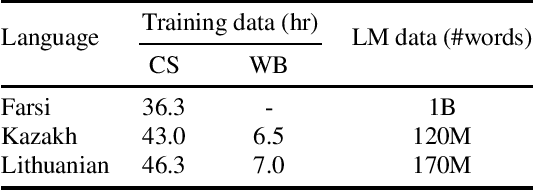
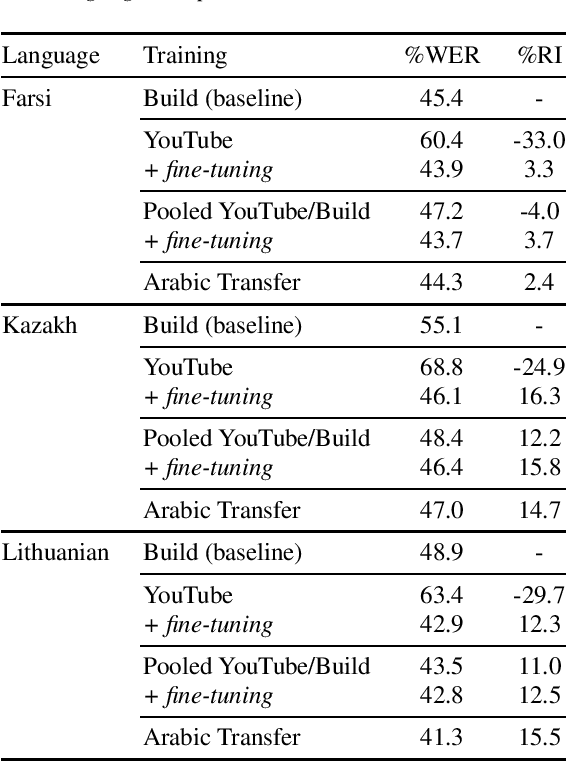
Semi-supervised training (SST) is a common approach to leverage untranscribed/unlabeled speech data to improve automatic speech recognition performance in low-resource languages. However, if the available unlabeled speech is mismatched to the target domain, SST is not as effective, and in many cases performs worse than the original system. In this paper, we address the issue of low-resource ASR when only untranscribed out-of-domain speech data is readily available in the target language. Specifically, we look to improve performance on conversational/telephony speech (target domain) using web resources, in particular YouTube data, which more closely resembles news/topical broadcast data. Leveraging SST, we show that while in some cases simply pooling the out-of-domain data with the training data lowers word error rate (WER), in all cases, we see improvements if we train first with the out-of-domain data and then fine-tune the resulting model with the original training data. Using 2000 hours of speed perturbed YouTube audio in each target language, with semi-supervised transcripts, we show improvements on multiple languages/data sets, of up to 16.3% relative improvement in WER over the baseline systems and up to 7.4% relative improvement in WER over a system that simply pools the out-of-domain data with the training data.