 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LSTM-CTC based ASR performance in domains with limited training data
Paper and Code
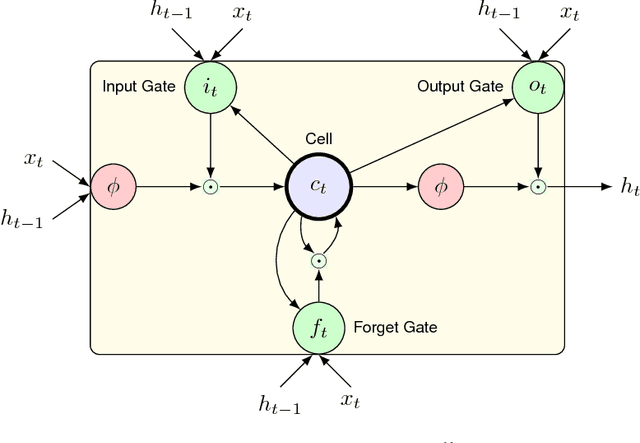


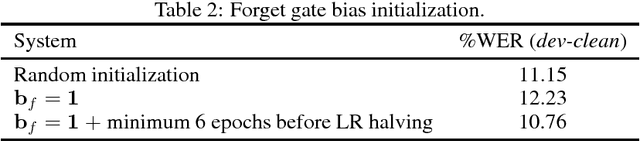
This paper addresses the observed performance gap between automatic speech recognition (ASR) systems based on Long Short Term Memory (LSTM) neural networks trained with the connectionist temporal classification (CTC) loss function and systems based on hybrid Deep Neural Networks (DNNs) trained with the cross entropy (CE) loss function on domains with limited data. We step through a number of experiments that show incremental improvements on a baseline EESEN toolkit based LSTM-CTC ASR system trained on the Librispeech 100hr (train-clean-100) corpus. Our results show that with effective combination of data augmentation and regularization, a LSTM-CTC based system can exceed the performance of a strong Kaldi based baseline trained on the same data.